Using Skylight to Solve Real-World Performance Problems [Part II: The Odin Project]
This post is the second in an ongoing three-part series, and is a write-up of the talk we gave at RailsConf 2018. You can find the slides here, or read Part I of the series.
In Part I of the Skylight for Open Source Series, we delved into some common forms of optimizations that Skylight helps pinpoint in your applications. In this installment, we'll dig into some more complex performance issues in another open source app: The Odin Project.
An Introduction To The Odin Project
The Odin Project is an open source community and curriculum for learning web development. Students build portfolio projects and complete lessons that are constantly curated and updated with the latest resources. They offer completely free courses like Ruby, Rails, JavaScript, HTML, and CSS. Once a student climbs the technical ladder, there's even a course on how to go about getting a job in the industry, walking you through things like job searching, interviews, and much more.
One challenge of running an app like this comes from the size of the community. There is a lot of information to keep track of for each student, including which courses they have taken as well as their progress within each course. With over a hundred thousand students, this adds up very quickly.
For example, let’s take a look at the work involved in rendering these beautiful badges:
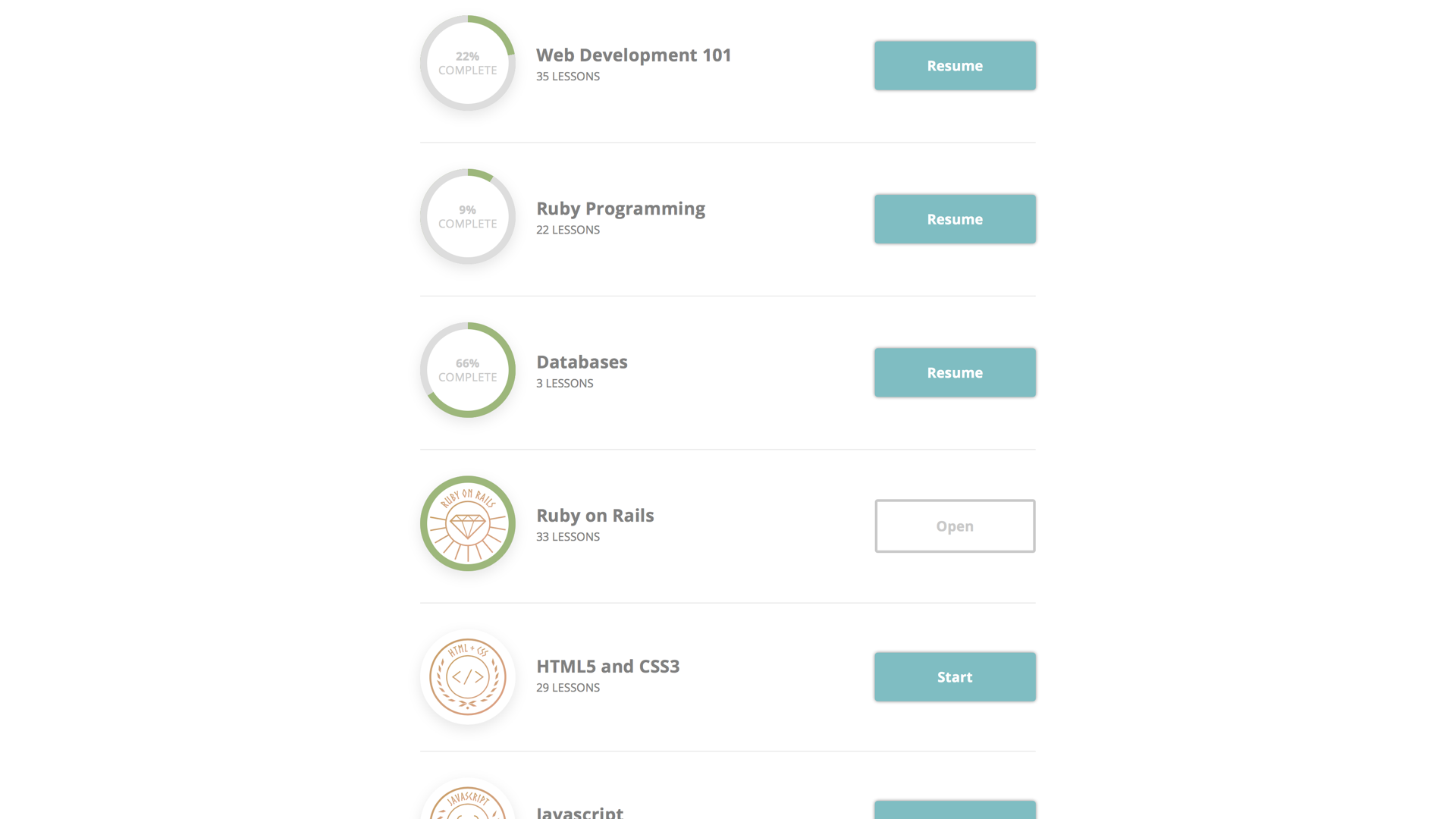
As we might imagine, we need to know two things to be able to render a badge: the lessons belonging to the course, and which of those lessons the student has completed.
# SELECT * FROM lesson_completions WHERE student_id = 13;
👇
LESSONS COMPLETED
PERCENTAGE = ————————————————— x 100%
LESSONS AVAILABLE
👆
# SELECT * FROM lessons WHERE course_id = 1;
The first part of this is pretty straightforward, and is just a simple SELECT query; the second part involves a join table called lesson_completions. This is pretty standard too: there is both a lesson_id column and a student_id column.
(Since we are showing badges for every course on this page, we are making a single query to fetch all the completion records for the current student in order to avoid the N+1 query problem. We also simplified the example slightly to omit a secondary join table.)
However, according to Skylight, this second query takes up a noticeable amount of time on each request: not terribly slow, but definitely noticeable.
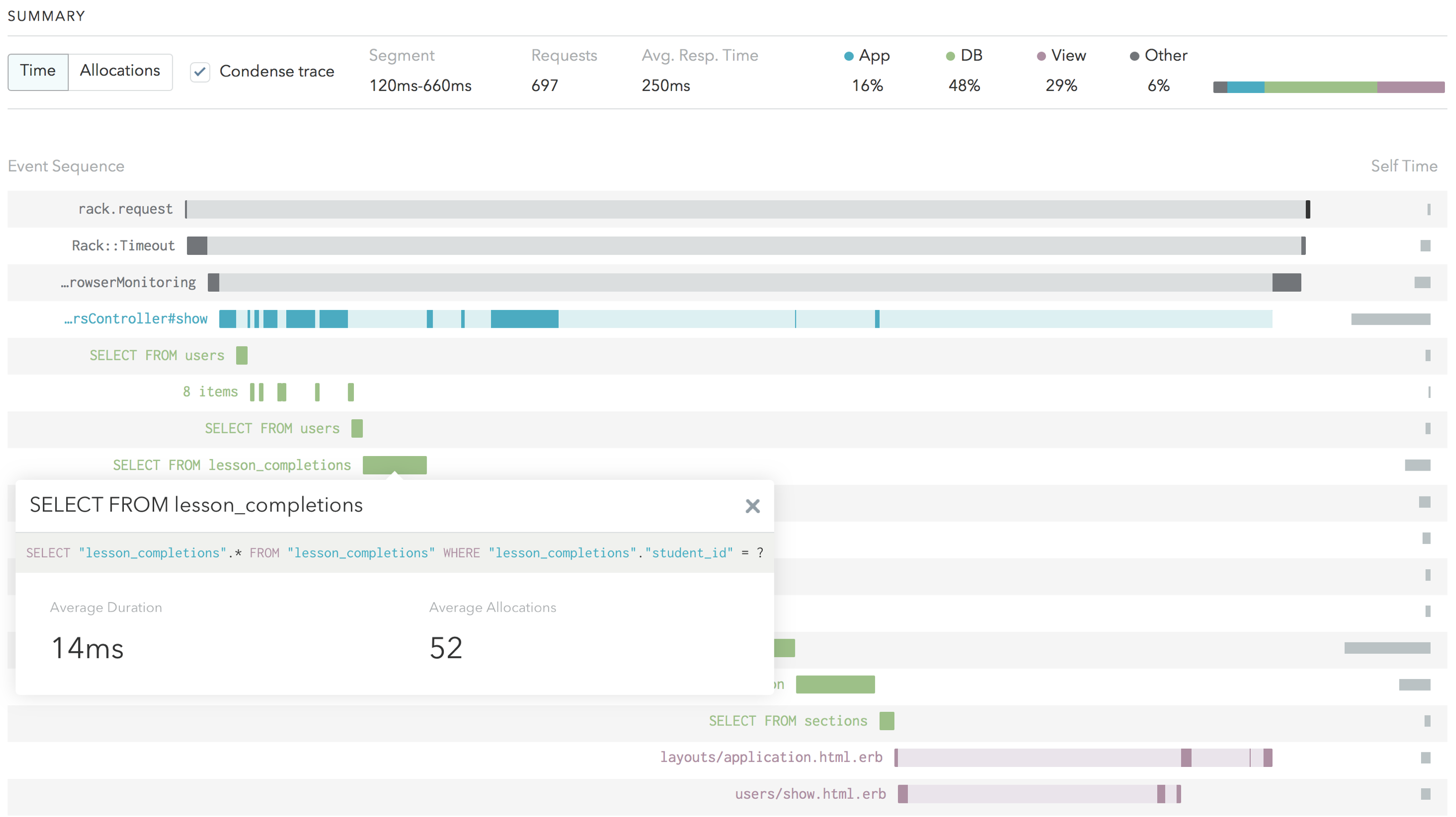
So the question is, can we make it faster?
Quicker Queries
As we may already know, databases rely on indexes to keep these kinds of queries fast. Essentially, we do a little more work when inserting the data in exchange for a significant performance boost when querying. In a lot of cases, the answer is simply to add the missing index, but this case is a little more nuanced than that.
Because a student shouldn’t be able to complete the same lesson twice, there is already a compound index on lesson_id and student_id that guarantees its uniqueness:
create_table "lesson_completions" do |t|
t.integer "lesson_id"
t.integer "student_id"
t.t.timestamps
t.index ["lesson_id", "student_id"], unique: true, using: :btree
end
Since we are only querying on the second field (student_id), is this compound index sufficient for our query?
For a long time, and for most databases, the answer would have been no. However, starting in version 8.1, Postgres is sometimes able to take advantage of the compound index for queries involving only the second column in that index. Unfortunately, even when that is possible, it’s still not as efficient as having a dedicated index for that second column.
We can confirm this by running an EXPLAIN on the query. As we'll see, if we have no indexes at all, Postgres will be forced to do a sequential scan, which could end up being fairly slow on a big table:
# using no indexes
LessonCompletion Load (57.2ms) SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
=> EXPLAIN for: SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
-----------------------------------------------------------------------
Seq Scan on lesson_completions (cost=0.00..4063.50 rows=49 width=28)
Filter: (student_id = 3074)
(2 rows)
Now, we'll add the compound index and try this again. We will observe that Postgres is using the compound index here, but this is still not as fast as it should be:
# using compound index
LessonCompletion Load (9.8ms) SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
=> EXPLAIN for: SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
------------------------------------------------------------------------------------------------------------------------------------
Index Scan using index_lesson_completions_on_lesson_id_and_student_id on lesson_completions (cost=0.42..3987.60 rows=49 width=28)
Index Cond: (student_id = 3074)
(2 rows)
Finally, we will add the dedicated index for the student_id column. Postgres is now able to fully take advantage of the index and improve the query performance noticeably:
# using single index
LessonCompletion Load (1.6ms) SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
=> EXPLAIN for: SELECT "lesson_completions".* FROM "lesson_completions" WHERE "lesson_completions"."student_id" = $1 [["student_id", 3074]]
-------------------------------------------------------------------------------------------------------------------
Index Scan using index_lesson_completions_on_student_id on lesson_completions (cost=0.42..9.29 rows=49 width=28)
Index Cond: (student_id = 3074)
(2 rows)
Note that none of this applies to the first column of a compound index. If we were to query on lesson_id alone, Postgres will be able to use the compound index just as efficiently, so there is no need to add a dedicated index for that case.
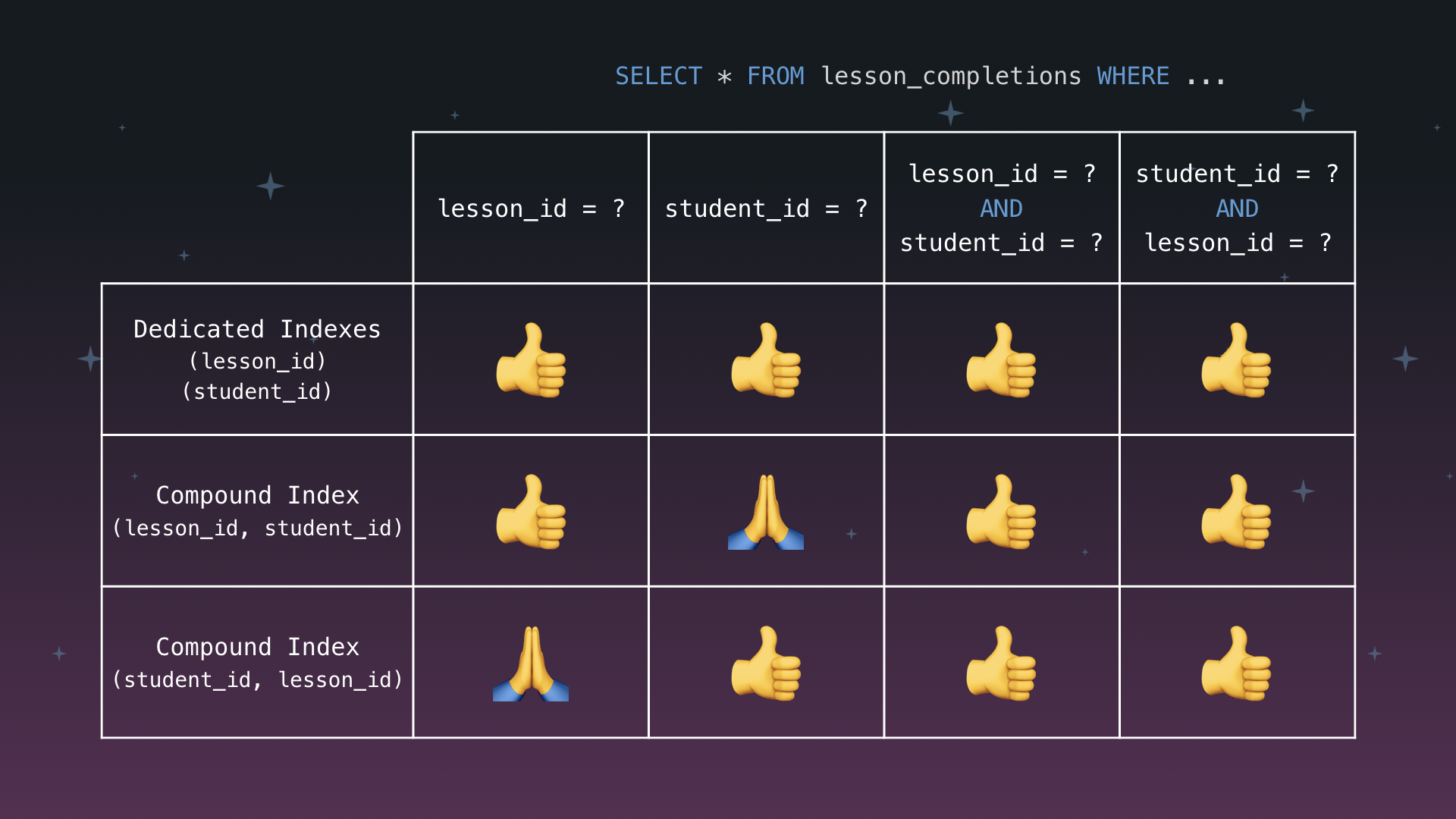
Here is a summary of what we have learned. First of all, Postgres is generally very smart about using multiple indexes for a single query, so we should always just start with individual indexes.
However, if we already need a compound index for other reasons, we should be sure to prioritize the field that we want to query separately, and put that first in the compound index. Alternatively, we can maintain a dedicated index for any additional columns by which we would like to query.
We were able apply what we learned here and submit a pull request to The Odin Project to improve this query’s performance.
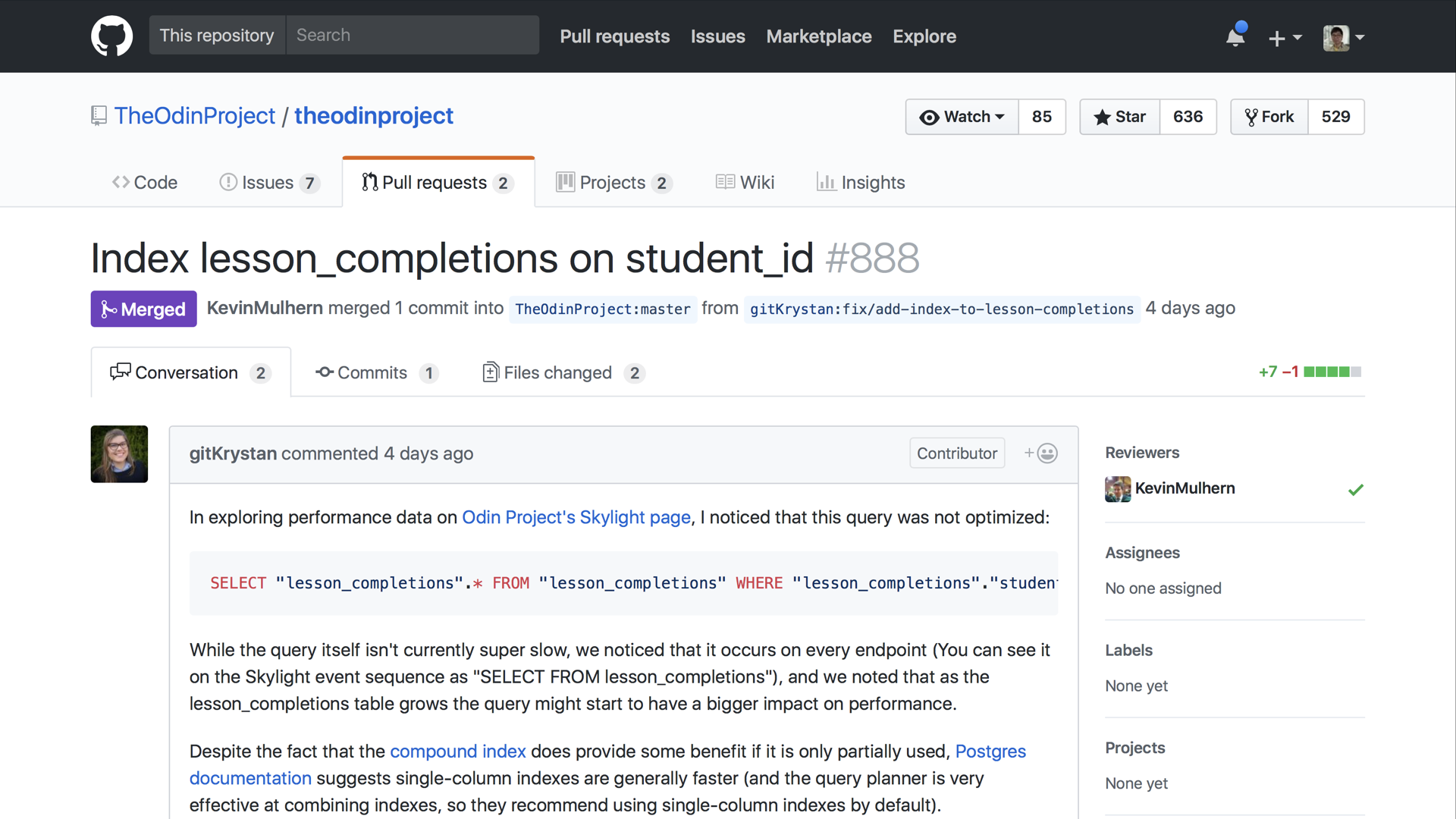
Clarifying Compound Indexes
While we were working on this particular optimization problem, we also noticed a similar case on the lessons table.
We found a compound index for slug and section_id, and wanted to query on section_id. So, we thought we could add a dedicated index for section_id as well.
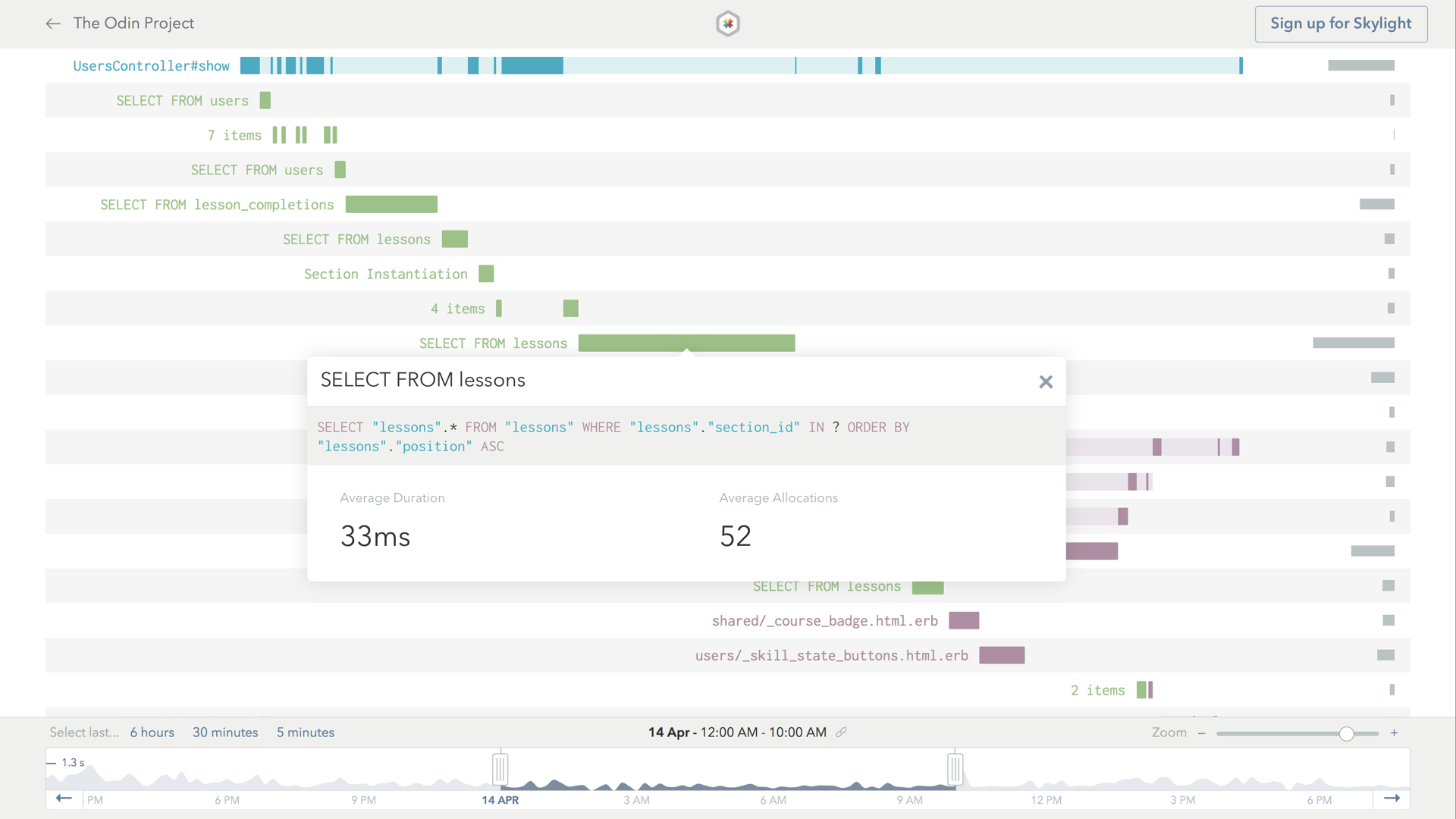
However, when we ran EXPLAIN, we noticed that Postgres wasn’t using our new index.
As it turns out, the lessons table was fairly small – less than 200 rows in total. When dealing with a small table like this, Postgres is actually able to do a sequential scan much faster than using the index. So, if we had added an index, it would just ended up being more work at insertion time, without any significant benefits.
The moral of the story is this: we should avoid optimizing prematurely, and always check our assumptions. It is often a better idea to just do the straightforward thing and let Skylight tell you what’s slow, rather than spending time investigating and optimizing your code.
Ultimately, we were able to figure out why this query was slow and created a second pull request to fix it. However, that's a story for for another time (for the super curious, there are some details in the pull request if you're interested 😉).
In part III of this series, we'll be exploring some caching complexities we while trying to optimize another open source app, Code Triage. Be sure to check back soon for the final installment in our Skylight for Open Source Series!
Interested in joining the Skylight for Open Source Program? Learn more and see other open source apps in action! Want to use Skylight for your work apps, too? Sign up for your 30-day free trial! Or refer a friend and you both get $50 in credit.