The Lifecycle of a Response
This post is a write-up of the talk I gave at RailsConf 2020. You can find the slides here.
Last year, the Skylight team gave a talk called Inside Rails: The Lifecycle of a Request. In that talk, we covered everything that happens between typing a URL into your browser to a request reaching your Rails controller action. But that talk ended with a cliffhanger:
Once we are in the controller action, how does Rails send our response back to the browser?
Together, these two talks paint a complete picture of the browser request/response cycle, the foundation that the whole field of web development is built on. But don't worry, you don't need to have seen that talk to understand this one. We'll start with a little recap of the important concepts.
Buckle up, because we're headed on a safari into the lifecycle of the response.

First, a little recap...
Let's get in our Safari Jeep and head on over to "skylight.io/safari". When we visit this page, we should see "Hello World." Let's go!
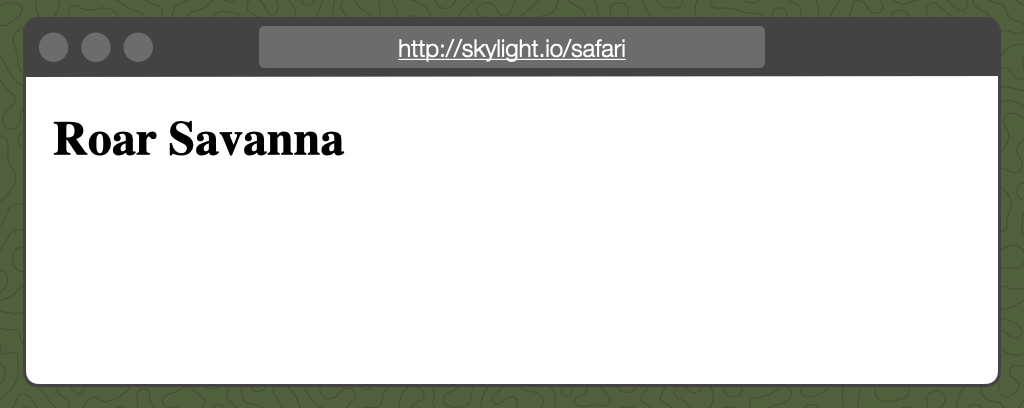
Oh no!!!! It appears that our safari server has been overtaken by lions. Instead of "Hello World" we see... "Roar Savanna"?! How did this happen? Let's find out! First, we need to answer this question:
When our browser connects to a server, how does the server know what the browser is asking for?

The browser and the server have to agree on a language for "speaking" to each other so that each can understand what the other is asking for. This set of rules is called "HTTP." It stands for hyper text transfer protocol, which is the language that both browsers and web servers can understand. "Protocol" is just a fancy word for "set of rules."
To get "skylight.io/safari", here is the simplest request that we could make. It specifies that it is a GET request, for the path /safari, using the HTTP protocol version 1.1, and it is for the host "skylight.io":
GET /safari HTTP/1.1
Host: skylight.io
And the HTTP-compliant response from the server looks something like this:
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Length: 12
Date: Thu, 25 Apr 2019 18:52:54 GMT
Roar Savanna
It specifies that the request was successful, gives a bunch of header information—like Content-Type, Content-Length, and Date—and finally, "Roar Savanna"—the response body.
But what happened in between sending this request and receiving the response?
The request is sent from the browser, through the interwebs, to our web server. (👋 handwave, 👋 handwave, check out last year's talk for more info.)
Then, another protocol kicks in. The "Rack protocol" is a set of rules for how to translate an HTTP-compliant request into a format that a Rack-compliant Ruby app (like Rails) can understand.
The web server (such as puma or unicorn) interprets the HTTP request and parses it into an environment hash, then calls your Rails app with this hash:
env = {
'REQUEST_METHOD' => 'GET',
'PATH_INFO' => '/safari',
'HTTP_HOST' => 'skylight.io',
# ...
}
MyRailsApp.call(env)
Rails receives the environment hash, passes it through a series of "middleware" and into your controller action. (👋 handwave, 👋 handwave, check out last year's talk for more info.)
In our controller, the lions have written something like this:
class SafariController < ApplicationController
def hello
# Get it? A savanna is a type of plain...
render plain: "Roar Savanna"
end
end
The Safari Controller has an action called hello that tells Rails to render a plaintext response that says "Roar Savanna."
Rails runs your controller code, passes it back through all of that middleware, then returns an array of three things: the status code, a hash of headers, and the response body. We'll call this the "Response Array."
env = {
'REQUEST_METHOD' => 'GET',
'PATH_INFO' => '/safari',
'HTTP_HOST' => 'skylight.io',
# ...
}
status, headers, body = MyRailsApp.call(env)
# The Response Array:
status # => 200
headers # => { 'Content-Type' => 'text/plain', 'Content-Length' => '12', ... }
body # => ['Roar Savanna']
The Rack-compliant web server receives this array, converts it into an HTTP-compliant plaintext response, and sends it on its merry way back to your browser. Roar Savanna!
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Length: 12
Date: Thu, 25 Apr 2019 18:52:54 GMT
Roar Savanna
Easy peasy, right?
But how did Rails know what to put in this array? And how does the browser know what to do with this response?
Read on to find out!
The Status Code
The first item in the response array is the "status code." Simply put, the status code is a three digit number indicating if the request was successful, or not, and why.
Status codes are separated into 5 classes:
1xxInformational (These are pretty rare, so we won't go into more detail.)2xxSuccess!!3xxRedirection4xxClient Error (for errors originating from the client that made the request)5xxServer Error (for errors originating on the server)
Standardized status codes help clients make sense of the response, even if they can't read English (or whatever human language the response body is written in). This allows the browser, for example, to display the appropriate UI elements to the user or in development tools.

Status codes also tell the Google crawler what to do: pages responding with 200 OK status codes will be indexed, pages responding with 500 errors will be revisited later, and the crawler will follow redirection instructions from pages responding with 300-series status codes.

For these reasons, we want to be as precise as possible when choosing a status code.
(Pro-tip: you can learn a lot more about status codes by going to https://httpstatuses.com/.)
The simplest responses are the ones that require no response body. Even better, we can tell the browser not to even expect a response body by choosing the correct status code.
For example, let's say our Safari Controller has an eat_hippo action:
class SafariController < ApplicationController
def eat_hippo
consume_hippo if @current_user.lion?
head :no_content # 204
end
end
The action allows the current user to consume the hippo as long as they are a lion. Then it responds with a simple 204, which means "the server has successfully fulfilled the request and there is no additional content to send in the response body." In Safari speak, that's "the lion successfully ate the hippo and we can expect the hippo to have no body"....or something.
In Rails, the head method is shorthand for "respond only with this status, headers, and an empty body." The head method takes a symbol corresponding to a status, in this case :no_content for "204."
Redirects
Another common set of status codes is the 300 series: redirects.
For example, if we send a GET request to "skylight.io/find-hippo", the find_hippo action redirects us to the oasis_url because it's the dry season and the hippos have moved to find water.
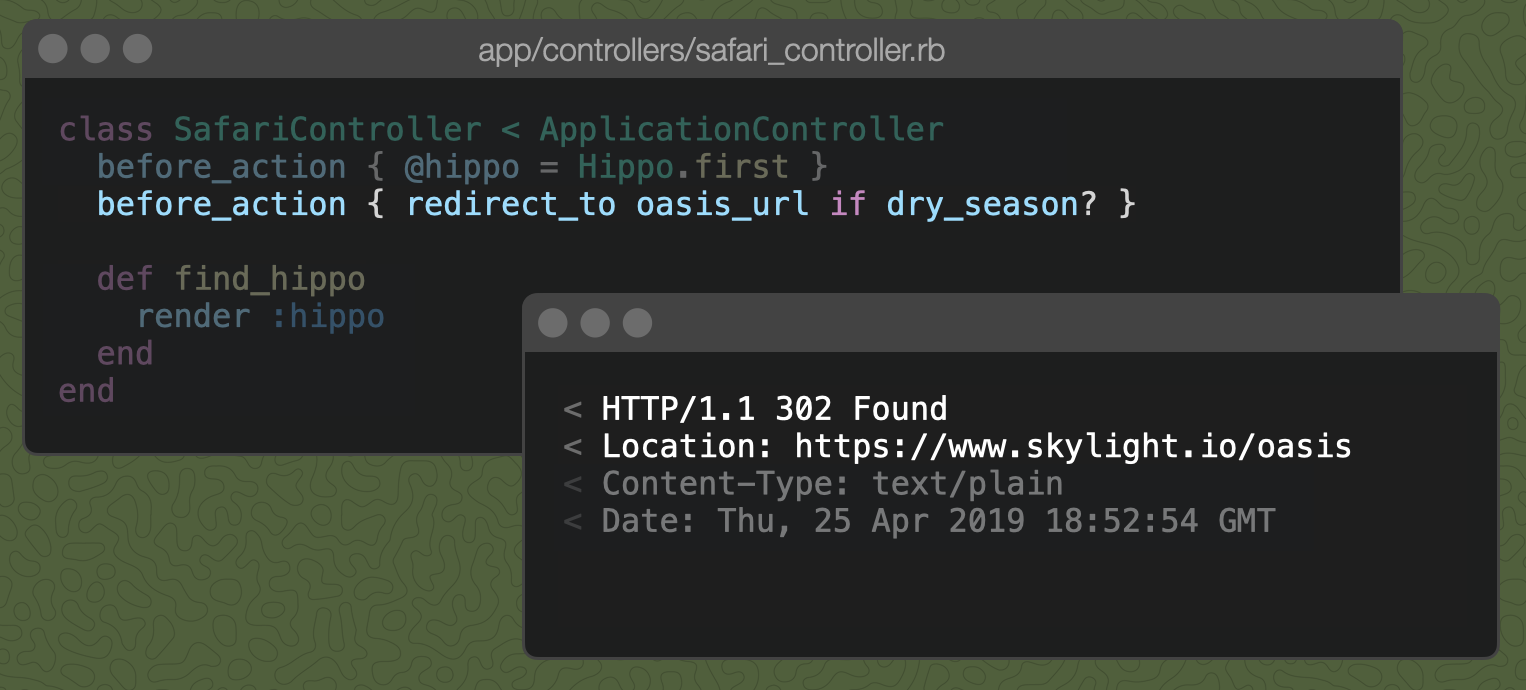
The Rails redirect_to method responds with a 302 Found status by default and includes a Location "header" (more on headers below) with the URL to which the browser should redirect. This status tells the browser "the hippo resides temporarily at the oasis URL. Sometimes the hippo resides elsewhere, so always check this location first."
But let's say the hippo has moved to the oasis permanently, maybe because of global warming. In this case, we could pass a status to redirect_to:
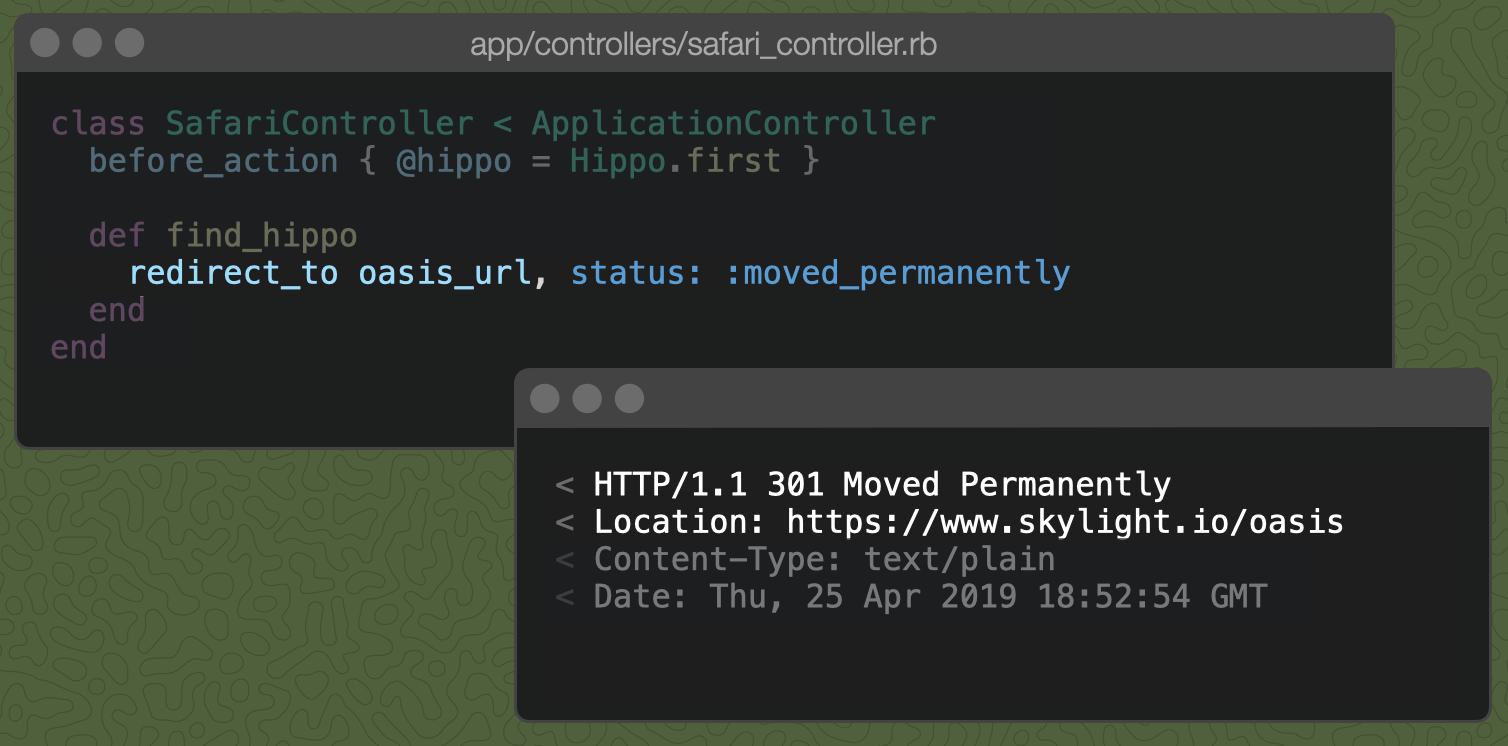
The :moved_permanently symbol corresponds with a 301 status code. This says to the browser, "the hippo has moved permanently to the oasis, so whenever you are looking for the hippo, look in the oasis." The next time you try to visit the hippo at /find-hippo, your browser can automatically visit /oasis instead without having to make the extra request to /find-hippo.
Alternatively, we could add the following to our routes file:
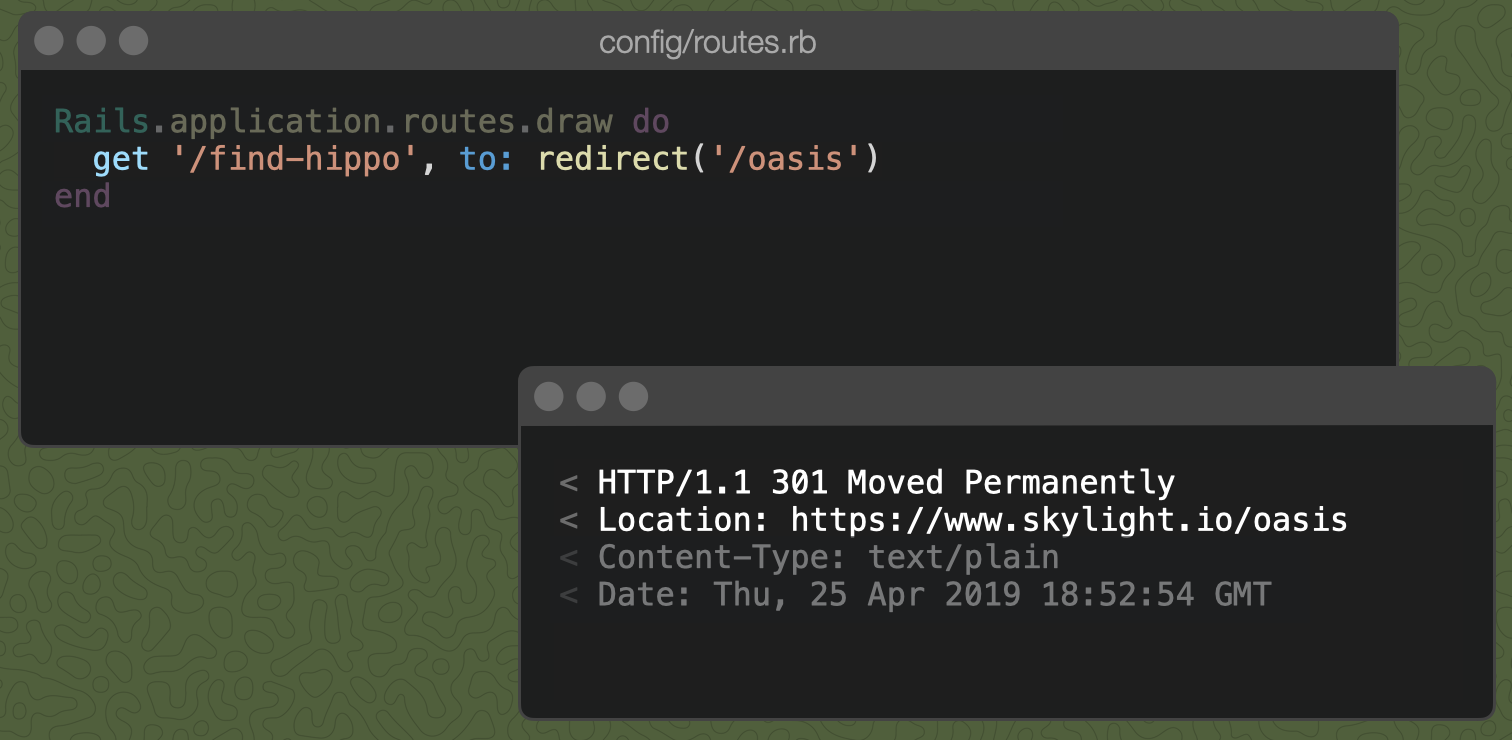
Handling the redirect in the routes file allows us to remove the controller action altogether. The redirect helper in the router responds with a 301 as well.
Danger! There is one important thing to note about the redirect_to method. The controller continues to execute the code in the action even after you've called redirect_to. For example, take a look at this version of the find_hippo action:
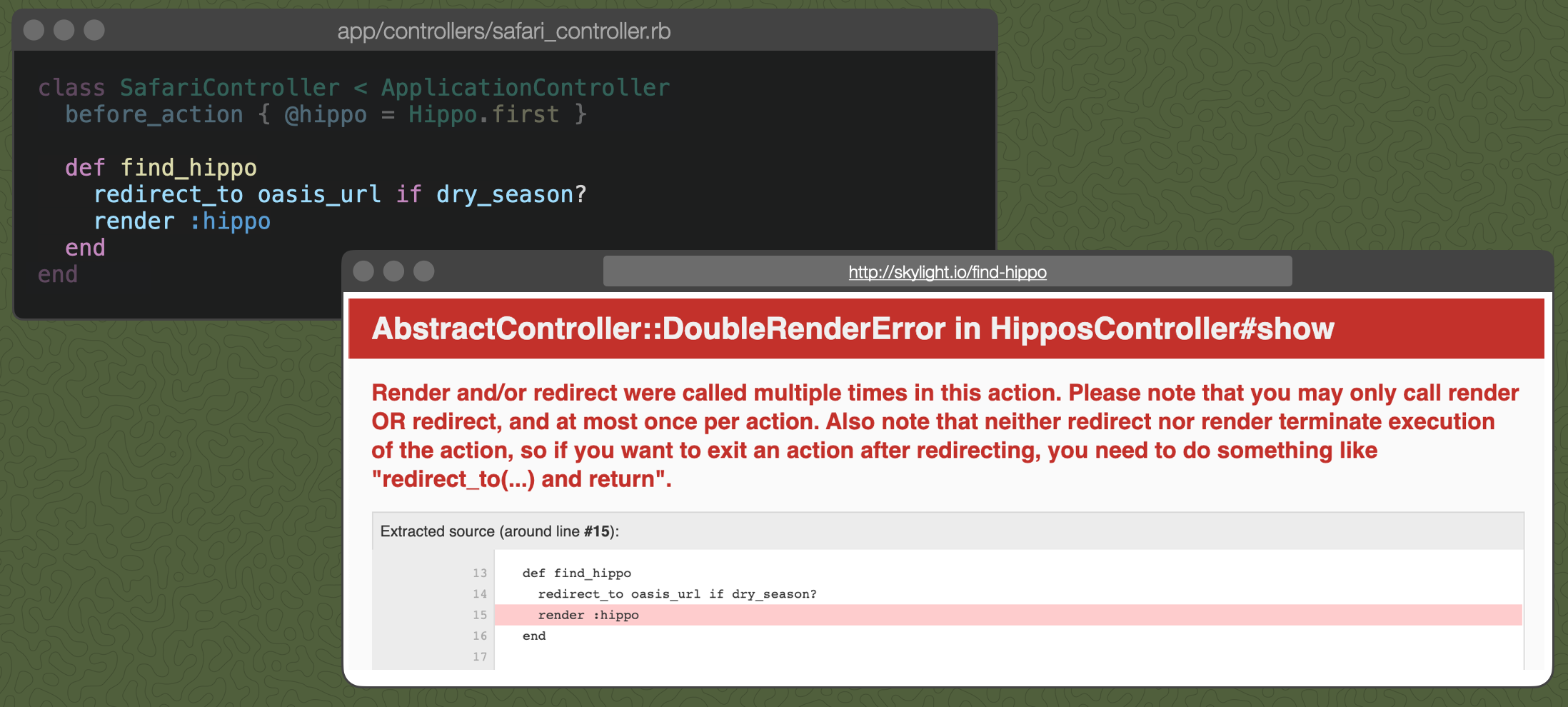
Because we didn't return when we called redirect_to, we actually hit both the redirect and render, so Rails doesn't know which response to respond with (a 301 or a 200?). Rails will throw a Double Render Error.
And fixed. By moving the redirect into a before_action, we ensure that render doesn't also get called because we now skip our entire controller action.
Status codes are a very concise way of conveying important information to the browser, but often, we need to include additional instructions to the browser about how to handle our response. Enter, headers.

Headers
Headers are included in a hash as the second item in the response array that our Rails app returns to our web server.
Headers are simply additional information about the response. This information might provide directions for the browser, such as whether and for how long to cache the response. Or it might provide metadata to use in a JavaScript client app.
We already talked about the Location header, which is used by the browser to know where it should redirect to.
Some other common headers you might see in a Rails app include:
- The
Content-Typeresponse header tells the browser what the content type of the returned content actually is—for example, an image, an html document, or just plain unformatted text. The browser checks this in order to know how to display the response in the UI. - The
Content-Lengthheader tells the browser the length in bytes of the response. For example, you might send aHEADrequest to an endpoint. That endpoint can respond withhead :okand aContent-Lengthso you can see how many bytes its response would be (in order to generate a download percentage, for example) without having to wait for the entire body to download (thus negating the usefulness of a download percentage). This header is set automatically by theRack::ContentLengthmiddleware. - The
Set-Cookieheader includes a semi-colon separated key-value string representing the cookies shared between the server and the browser. For example, Rails sets a cookie to track a user's requests across a session. Cookies in Rails are managed by a class called, no joke, theCookieJar.
These headers, and many more, are managed automatically by Rails. You can also set a header manually using response.headers like this:
response.headers['HEADER NAME'] = 'header value'
HTTP Caching
Headers can be used to give the browser directions about caching. "HTTP caching" is when your browser (or a proxy of the browser) stores an entire HTTP response. The next time you make a request to that endpoint, the response can be shown to you more quickly.

Caching behavior varies depending on the status code returned in the response, which is yet another reason that status codes are important.
The main header used to control caching behavior is, not surprisingly, called the Cache-Control header. Let's look at some examples.
(Pro-tip: You can turn on caching in development by running rails dev:cache.)
Hippos are pretty big and difficult to render, so maybe we should just render the hippo once, then cache it forever. The controller method http_cache_forever allows us to do this.
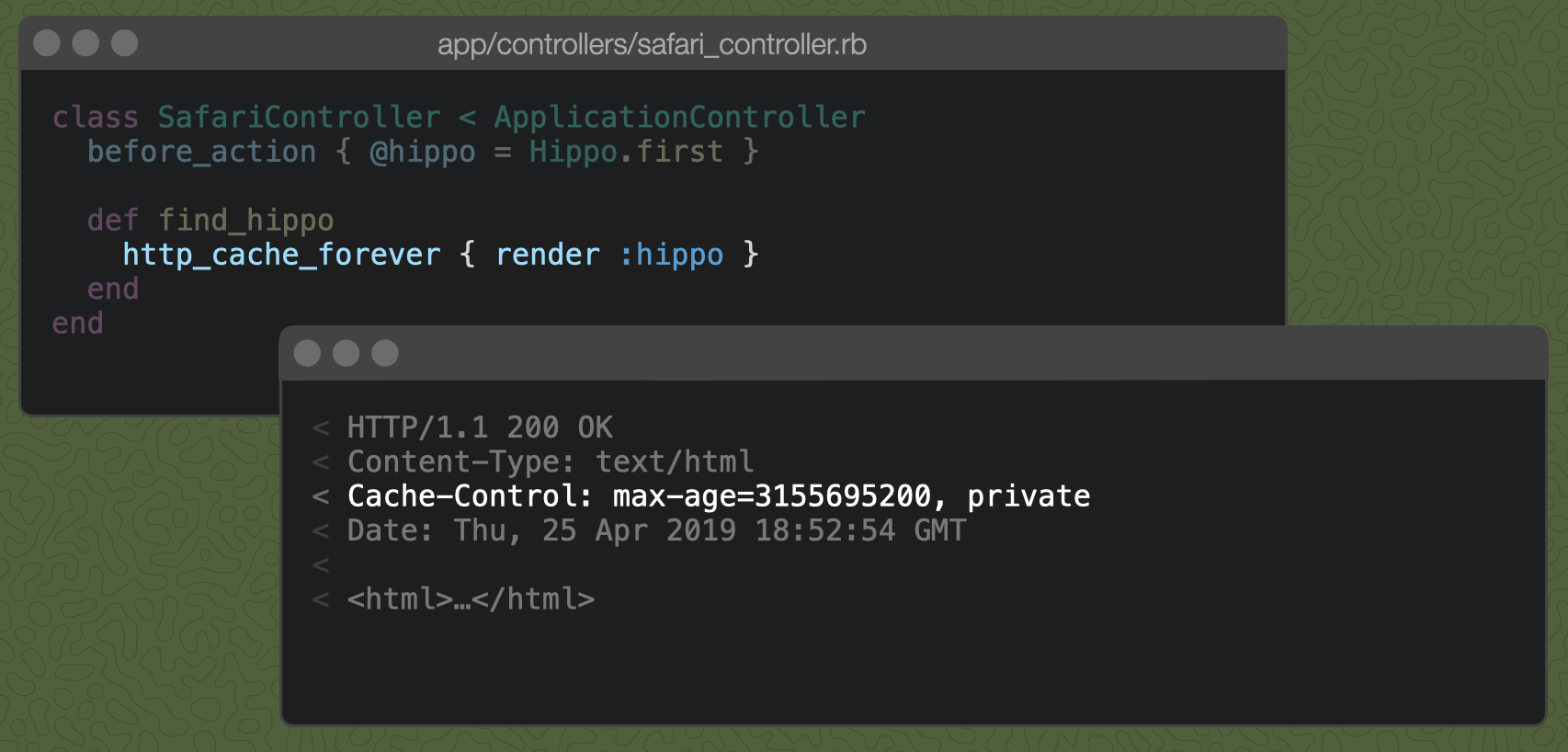
It sets the Cache-Control header's max-age directive to 3 billion, 155 million, 695 thousand and 200 seconds (or one century, which is basically forever in computer years). It also sets the private directive, which tells the browser and all browser proxies along the way that "This is a private hippo and she would prefer to be cached only by this user's browser and not by a shared cache."
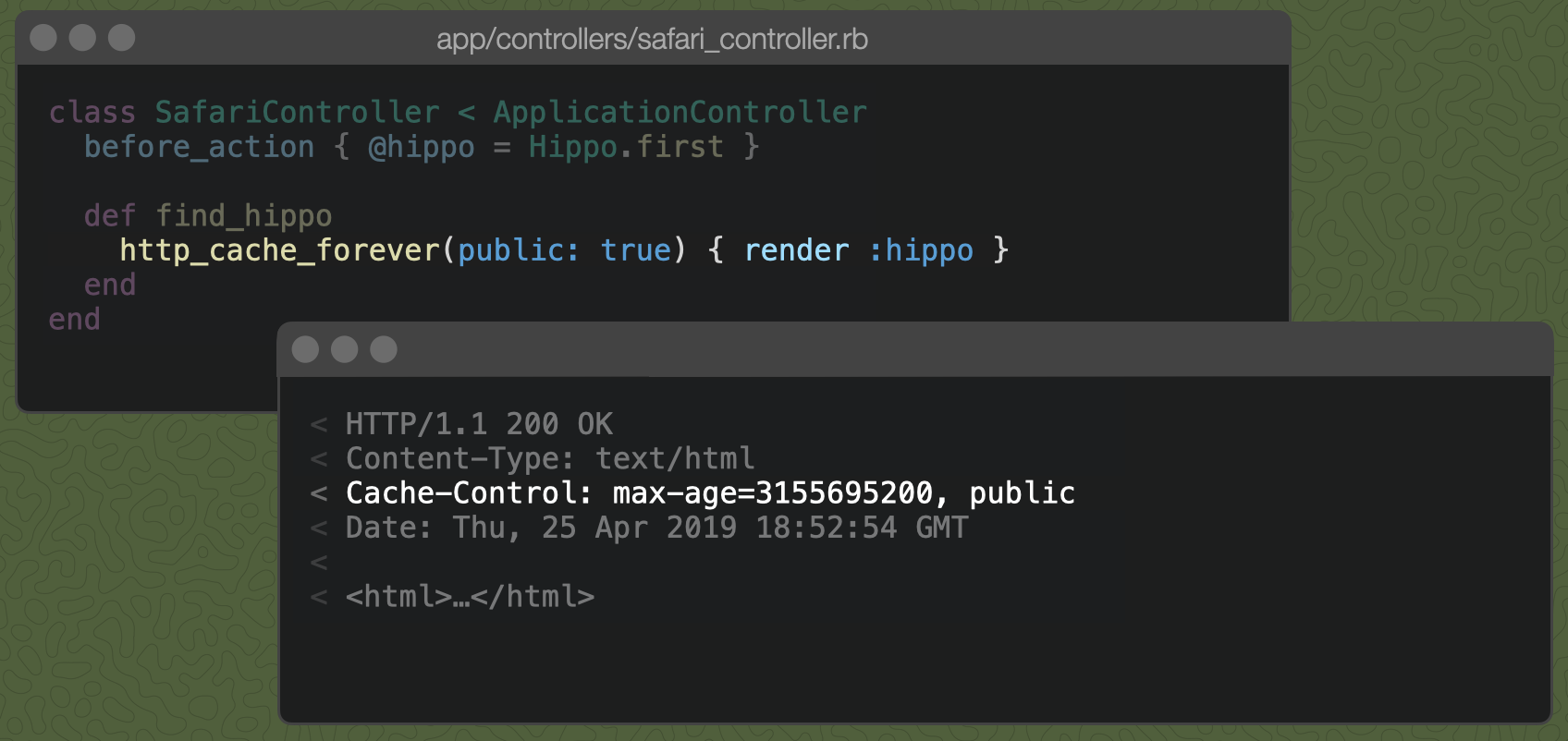
The private directive means only the account owner should have access to the response. The browser can cache it, but a cache between your server and the client, such as a "content distribution network" (or CDN), should not. If we want to allow caching by shared caches, we can just pass public: true to http_cache_forever to tell browser proxies that we're OK with them caching the hippo response along the way to the browser.
For another example of indefinite caching, let's include a picture of our hippo in the template. When we visit the page and look at the image source, we notice that Rails didn't just serve up the image at /assets/hippo.png. Instead, it served the image at /assets/hippo-gobbledygook.png.
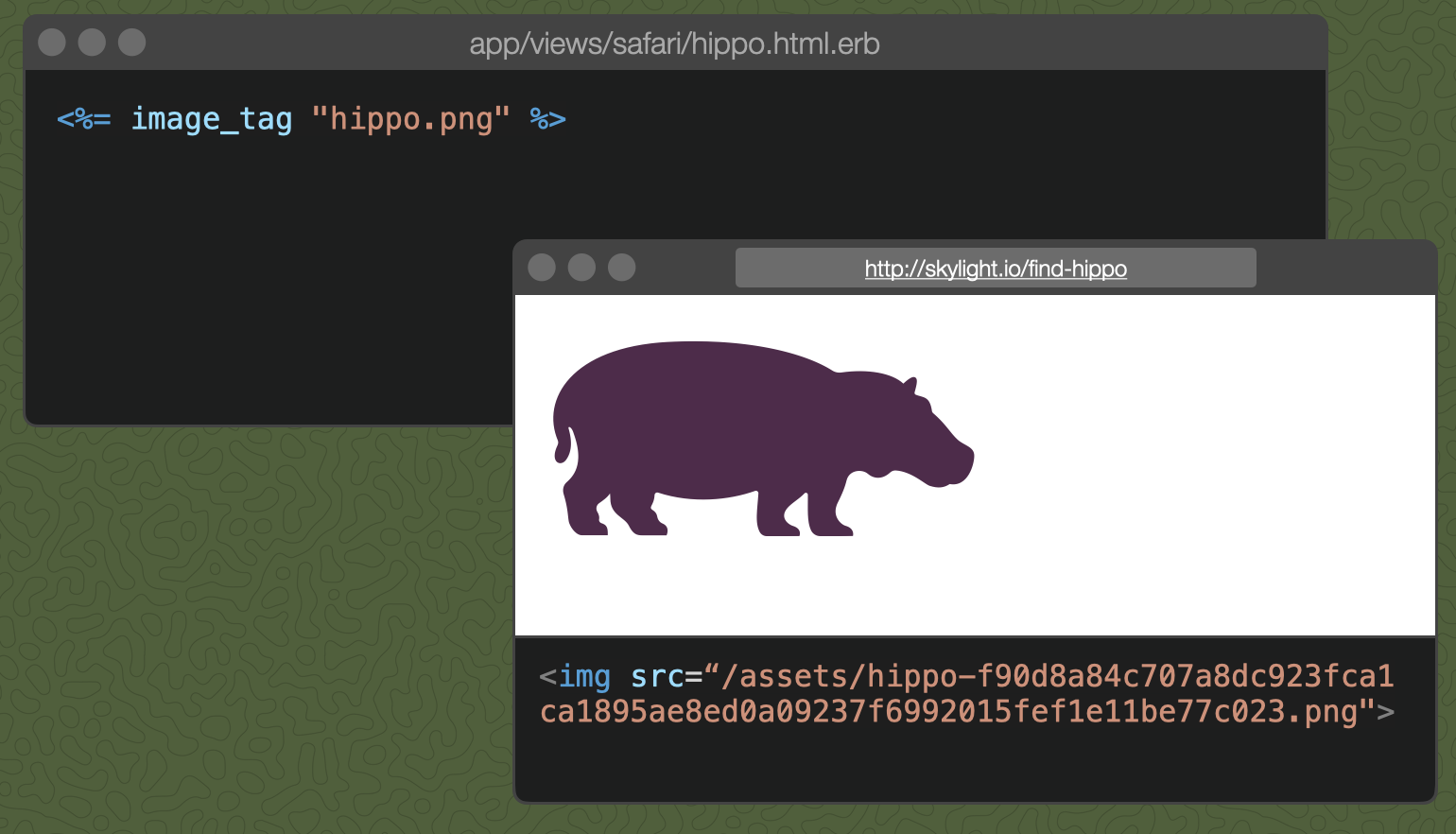
What is that about?
When the server serves our image, it sets the Cache-Control header to the equivalent of http_cache_forever. Browsers and browser proxies, like the CDN I mentioned before, will cache that hippo pic forever.
But what if we change the picture? How will our users access the most up-to-date hippo pix on the interwebs?!
The answer is "fingerprinting." The "gobbledygook" is actually the image's "fingerprint," and it's generated every time the Rails asset pipeline compiles the image based on the content of the image. If the image changes, the fingerprint linked in the html changes, and instead of showing the user the cached hippo pic, the browser will retrieve the new version of the image.
OK...back to response caching...
Was it really smart to cache the entire hippo forever? Hippos only live for about 40 years, and surely they change throughout their lives? Maybe we should only cache the hippo for an hour.
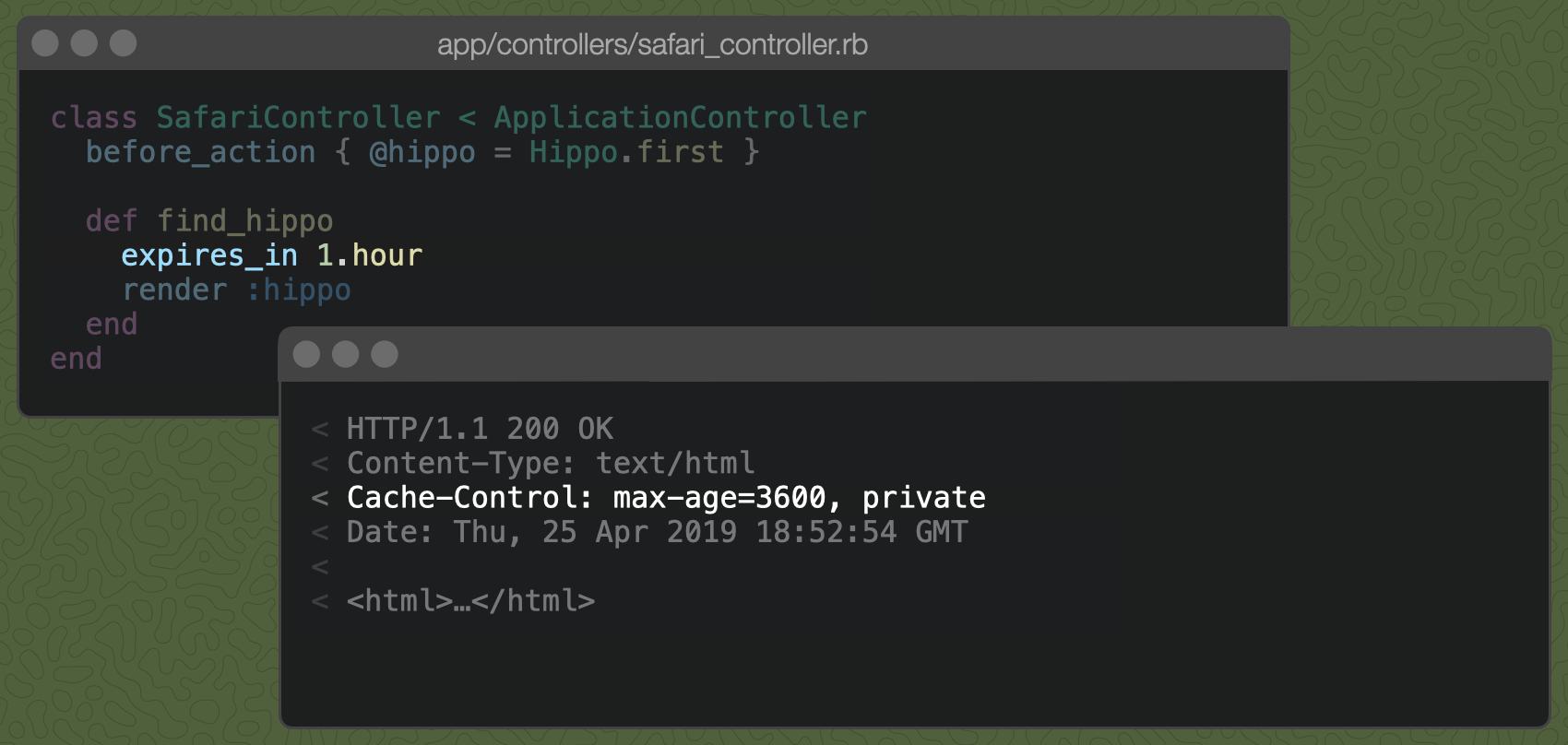
The expires_in controller method sets the Cache-Control header's max-age directive to the given amount of time. Now, our browser will reload the hippo if we visit the page again after an hour.
But how do we know the hippo won't change within that hour?
This is hard to guarantee. It sure would be nice if we could ask the server if the hippo has changed and only use the cache if the hippo has not changed.
Well, I have good news for you! This is the default behavior with no caching-specific code whatsoever!
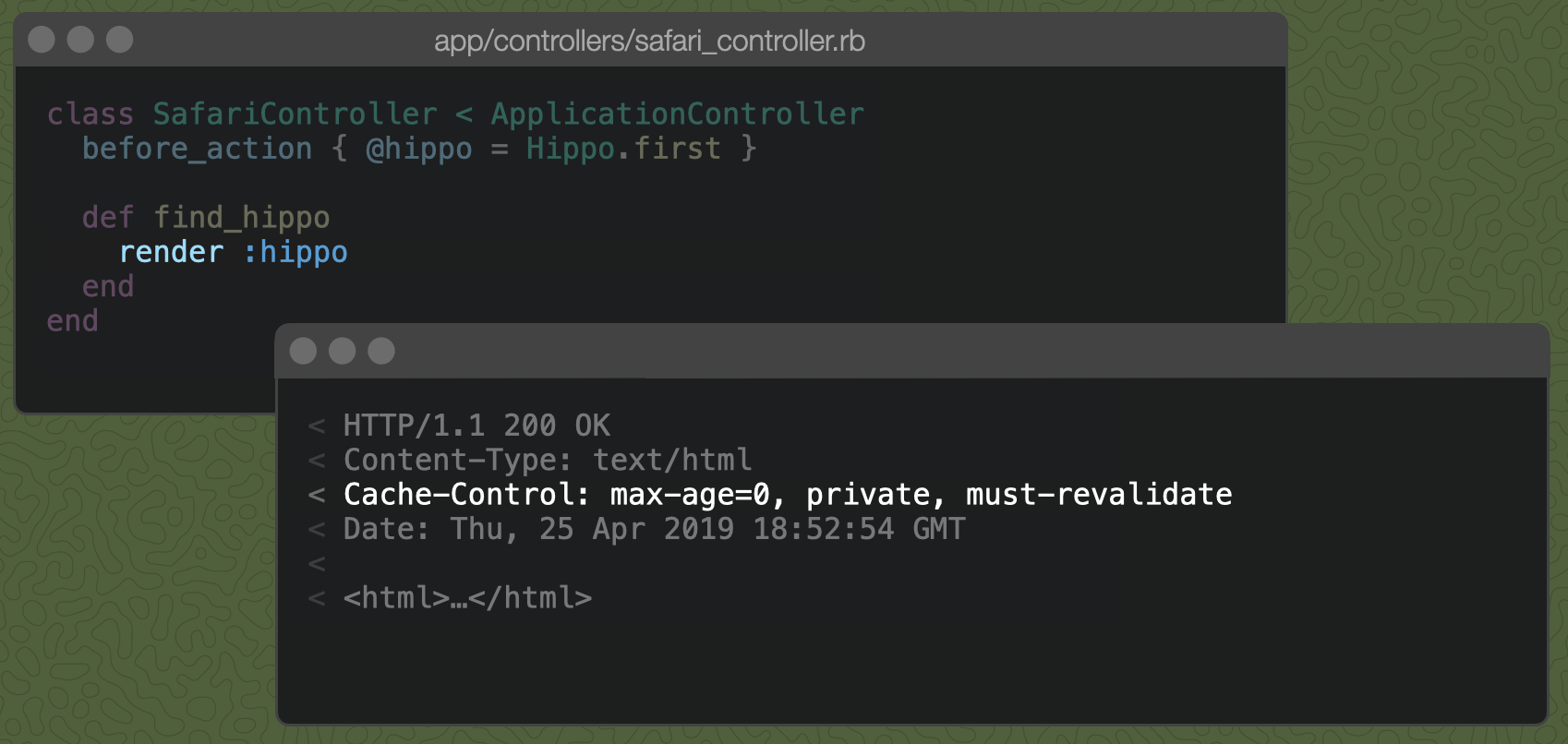
Rails adds the must-revalidate directive to the Cache-Control header. This means that the browser should revalidate the cached response before displaying it to the user. Rails also sets the max-age directive to zero seconds, meaning that the cached response should immediately be considered stale. Together, these directives tell the browser to always revalidate the cached response before displaying it.
So how does this "revalidation" work?
The first time we visited the /find-hippo endpoint, Rails ran our code to create the response body, including doing all that work to find and render the hippo. Before Rails passes the body along to your server, a middleware called Rack::ETag "digests" the response body into a unique "entity tag", similar to the asset fingerprints we talked about before.
# a simplified Rack::ETag
module Rack
class ETag
def initialize(app)
@app = app
end
def call(env)
status, headers, body = @app.call(env)
if status == 200
digest = digest_body(body)
headers[Etag] = %(W/"#{digest}")
end
[status, headers, body]
end
private
#...
end
end
Rack::Etag then sets the ETag response header with this entity tag:
Cache-Control: max-age=0, private, must-revalidate
ETag: W/"48a7e47309e0ec54e32df3a272094025"
Our browser caches this response, including the headers. When we visit this page again, our browser notices that the cached response is stale (max-age=0) and that we've requested that it "revalidate." So, when our browser sends the GET request, it includes the entity tag associated with the cached response back to the server via the If-None-Match request header:
GET /find_hippo HTTP/1.1
Host: skylight.io
If-None-Match: W/"48a7e47309e0ec54e32df3a272094025"
The server again runs our code to create the response body—including doing all the work to find and render the hippo again—then passes the body along to Rack::ETag again. And again, Rack::ETag digests the response body into the unique entity tag and sets the Etag response header.
Now, the next middleware in the chain, Rack::ConditionalGet checks if the new ETag header matches the entity tag sent along by the If-None-Match request header:
# a simplified Rack::ConditionalGet
module Rack
class ConditionalGet
def initialize(app)
@app = app
end
def call(env)
status, headers, body = @app.call(env)
if status == 200 && etag_matches?
status = 304
body = []
end
[status, headers, body]
end
private
def etag_matches?
headers['ETag'] == env['HTTP_IF_NONE_MATCH']
end
end
end
If they match, Rack::ConditionalGet will replace the status with 304 Not Modified and discard the body. The browser doesn't need to wait to download the redundant body, and the 304 status tells the browser to just use the cached response instead.
If the new Etag does not match, the server just sends the full response along with the original status code. The browser will now render a fresh hippo.
It seems like the server is still doing a lot of work rendering an entire hippo just to generate and compare ETags. If we know that the only reason that the response body is changing is because the hippo herself is changing, surely there is a better way?
Enter, the stale? method.
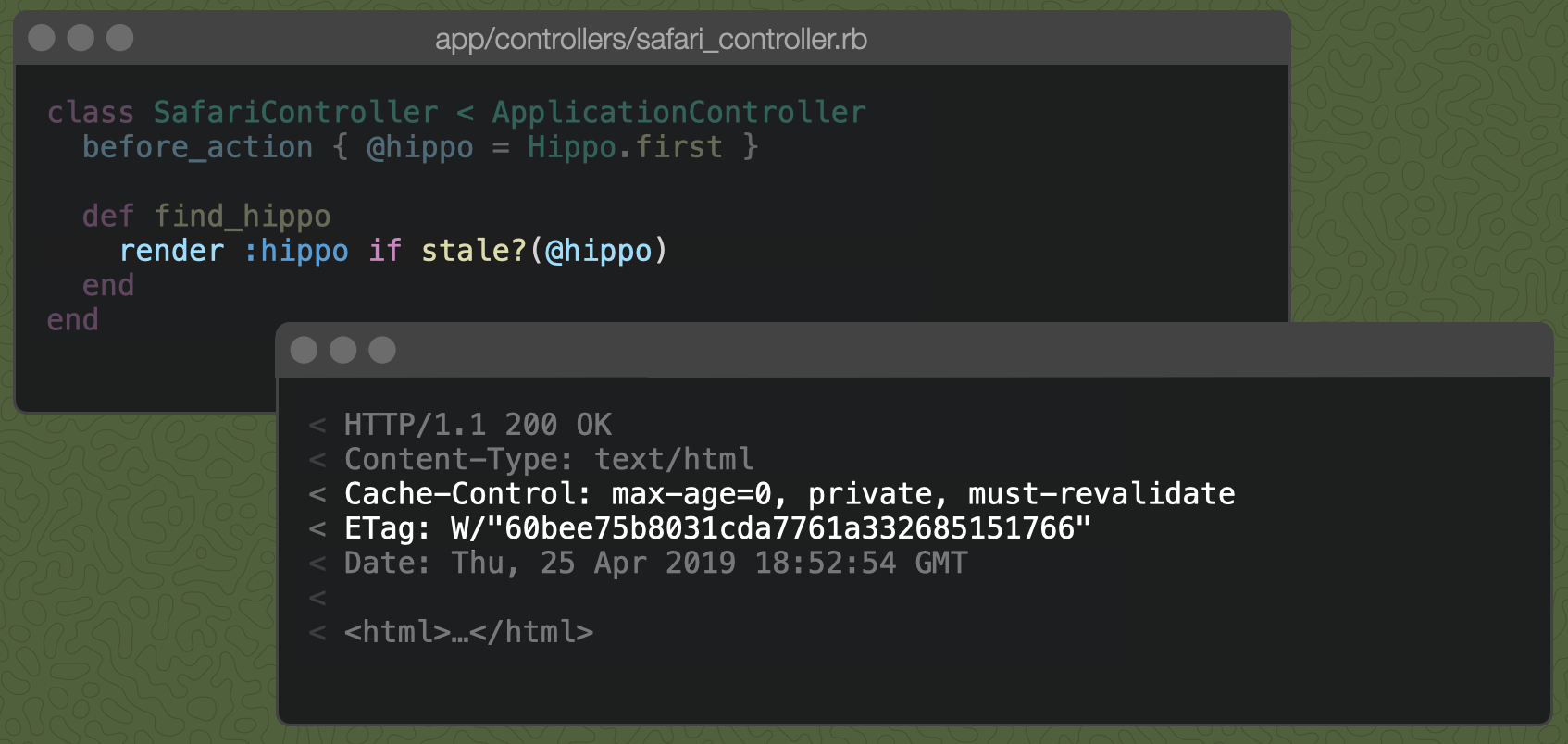
Now, our action says to render the hippo only if she is stale. We still get the same caching headers as we did with the default action, but the Etag is different even though our response body is identical. What changed here?
The stale? method tells Rails not to bother rendering the entire response body to build the ETag. Instead, just check if the hippo herself has changed and build the ETag based on that. Under the hood, Rails just generates a string based on a combination of the model name, id, and updated_at (in this case, "hippo/1-20071224150000"), then runs that through the ETag digest algorithm. This saves the server all of the effort of rendering the entire body to generate the ETag.
And finally, what if the hippo is so private that she never ever wants to be cached? Weirdly, Rails doesn't yet have a built-in method to do this, so you have to set the Cache-Control header directly.
![A Rails controller action with `response.headers["Cache-Control"] = "no-store" and the resulting Cache-Control header: no-store](https://storage.ghost.io/c/00/b5/00b5e7c8-3dda-42c0-84ad-84f61d994830/content/images/2020/05/image-23.png)
The no-store directive says that the response may not be stored in any cache, be it the browser or any proxies along the way. This is not to be confused with the poorly-named no-cache directive, which despite its name means that the response can be stored in any cache, but the stored response must be revalidated every time before it can be used.
Now that we've used the status code and headers to communicate to the browser what to do with our response, we should probably talk about the most important part of many responses: the body.
The Response Body
The body is the final part of the response array. It is a string representing the actual information the user has requested.
When we make a request to /find-hippo, how does Rails convert the code we wrote in our controller and view into an html page about a specific hippo? Let's find out!
Content Negotiation
When we visit "skylight.io/find-hippo" in the browser, our Rails app serves up an html response. We can verify this by looking at the Content-Type response header:
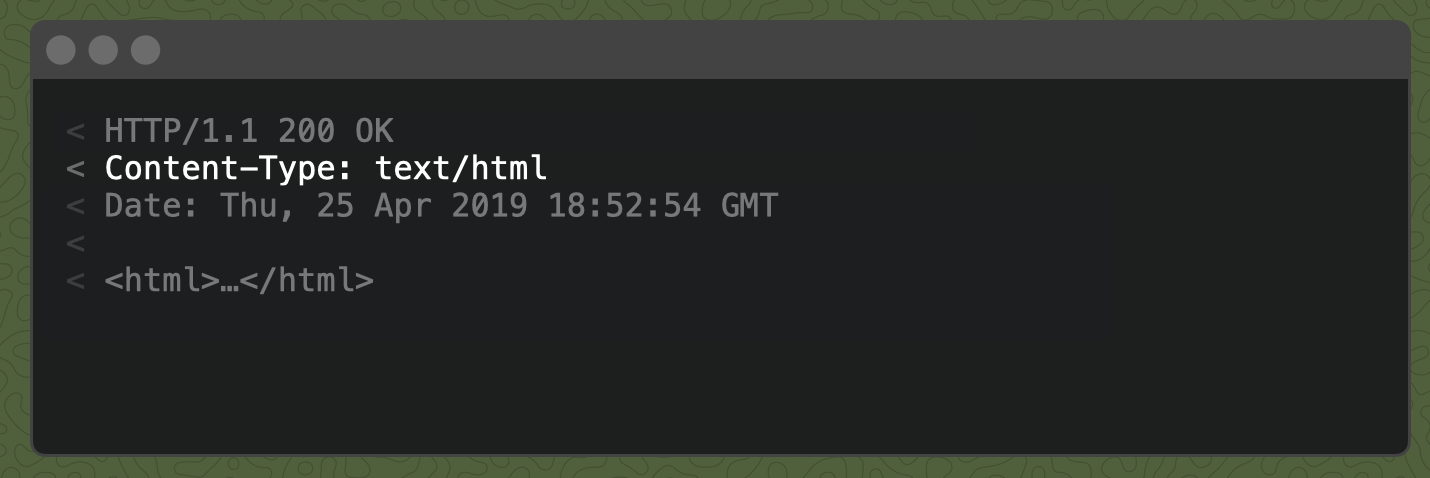
How did Rails know to respond with html?
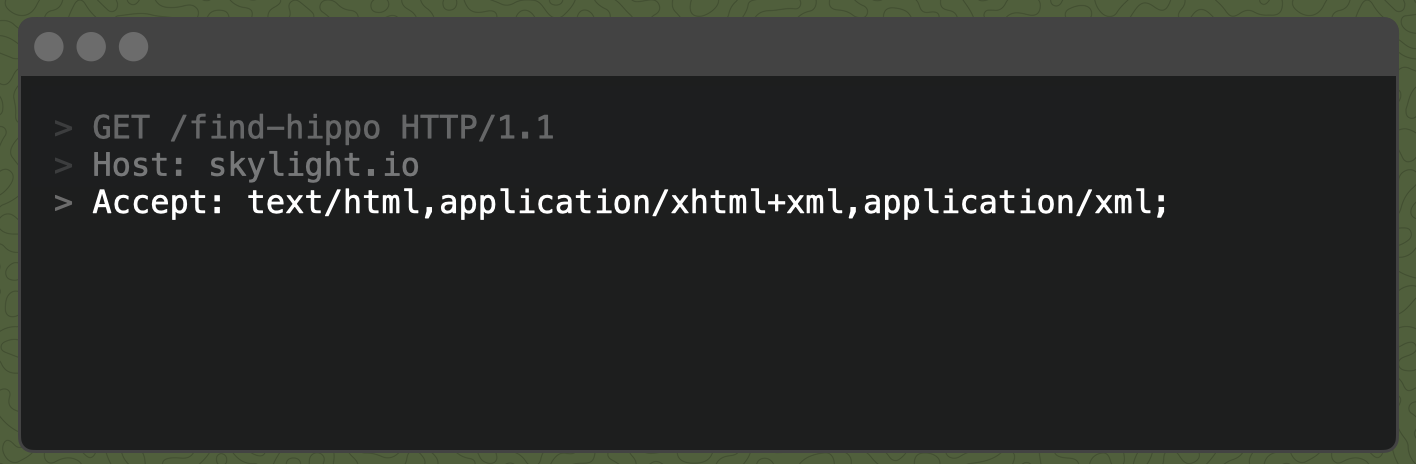
Rails looks first at any explicitly requested file-extensions, for example "skylight.io/find-hippo.html". If none is provided, which is the case with the request we made to "skylight.io/find-hippo", then it looks at the Accept request header.
Our Safari browser defaults this Accept request header to text/html, indicating it would prefer to receive the html content-type (formatted as a "MIME type") in the response. It also says that if there is no html version available, this browser is happy to accept an xml version instead.
The render method we call in our controller looks for the template with the extension matching the requested content-type, so in this case safari/hippo.html.erb. It also sets the Content-Type header to match the rendered body.
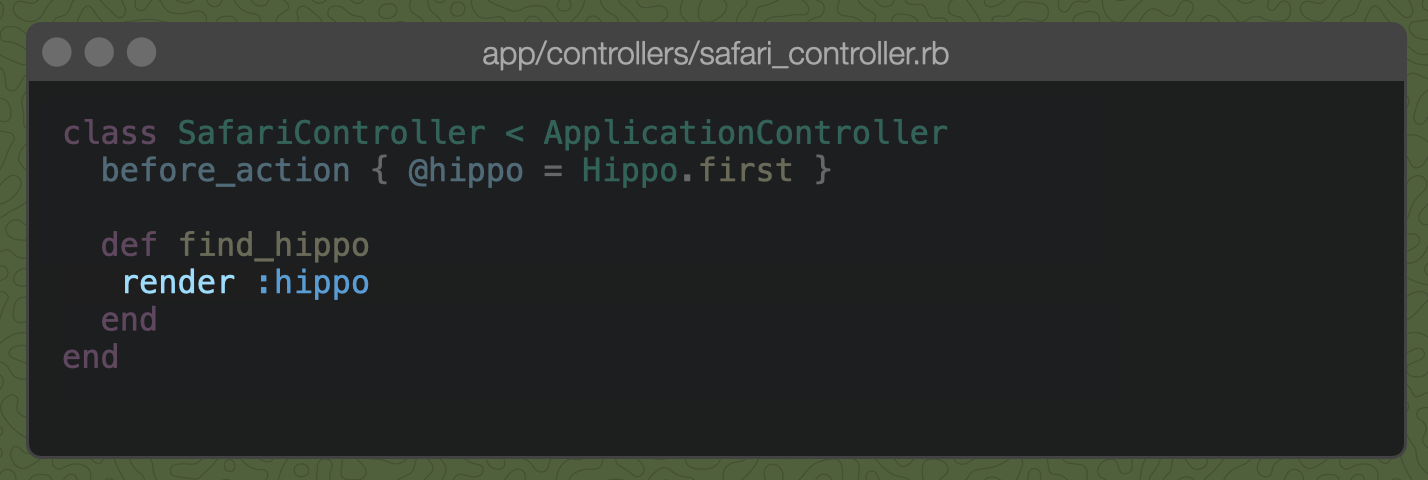
We want a json hippo too, so let's make a request to /find-hippo.json:
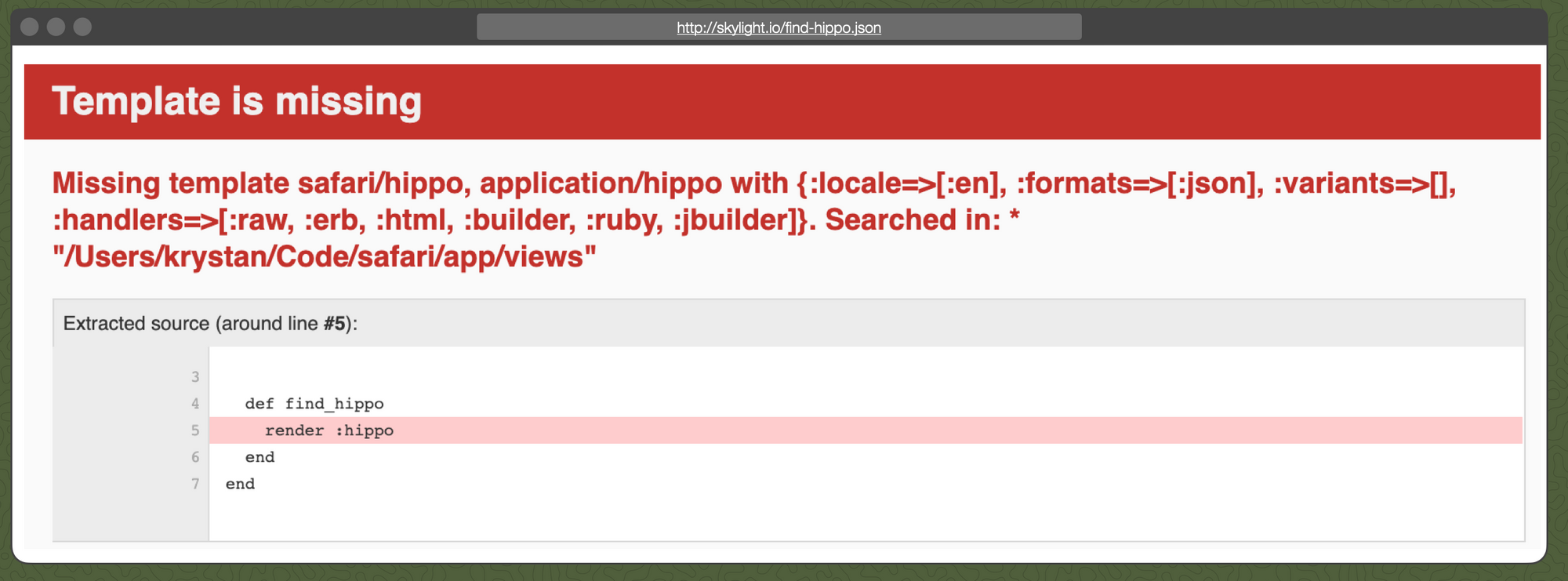
Oops! We don't have a template for a json hippo yet. We could add one, or we can add a respond_to block to handle the different formats:
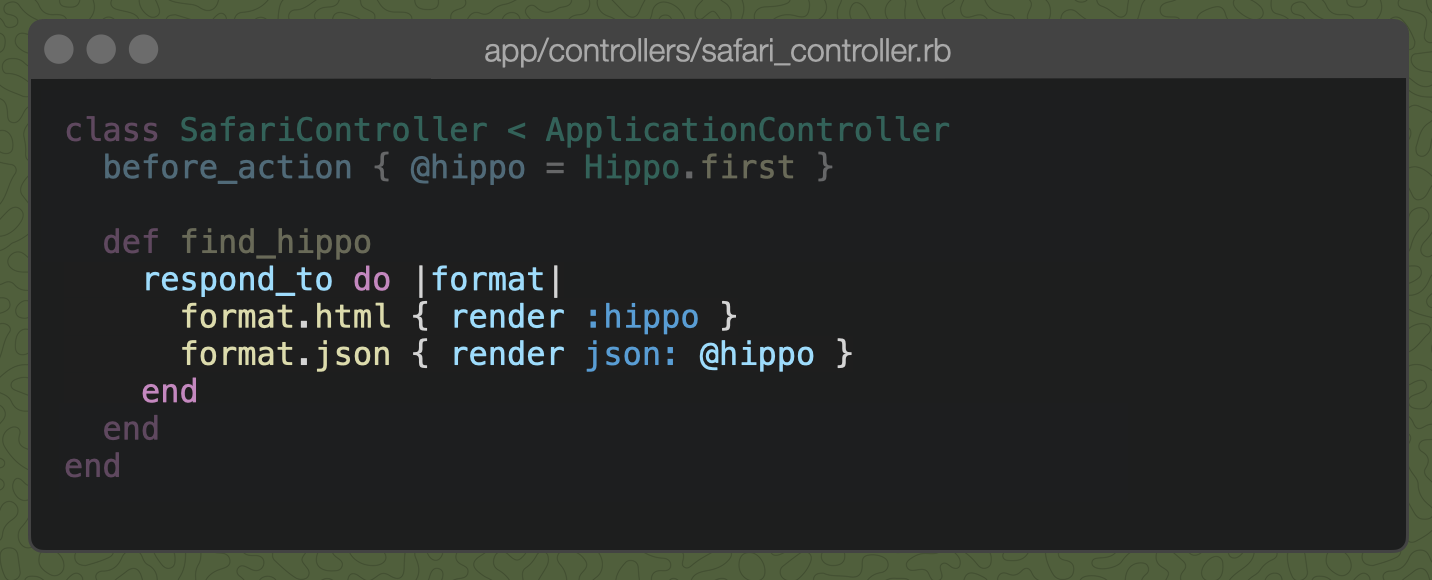
Now, if we request /find-hippo.json, we get the json hippo:
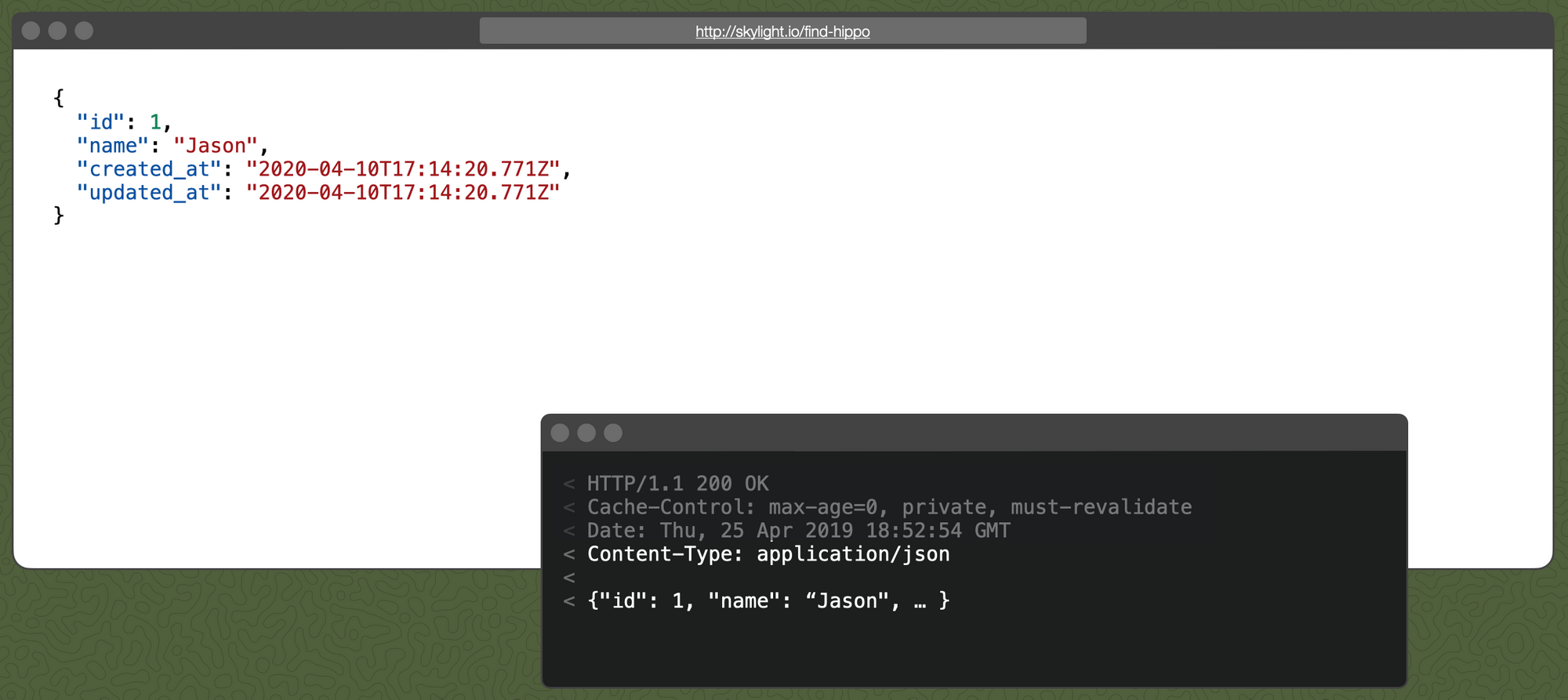
Interestingly, browsers are not actually required to obey the Content-Type header and might try to "sniff" out the type based on the contents of the file. For this reason, Rails sets the X-Content-Type-Options header to nosniff to prevent this behavior:
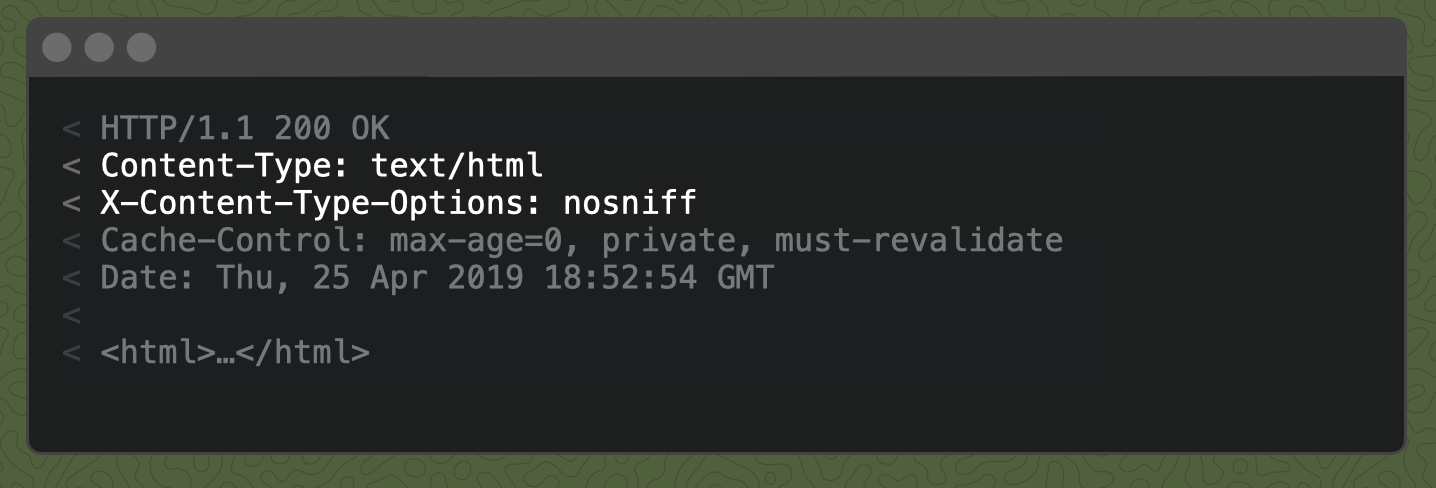
Template Rendering
There are three ways our Rails controllers can generate a response. We've already talked in depth about two of those ways: the redirect_to and head controller methods generate responses with status codes, headers, and empty bodies. Only the render method generates a full response that includes a body.
For our /find-hippo example, let's say the template looks like this:
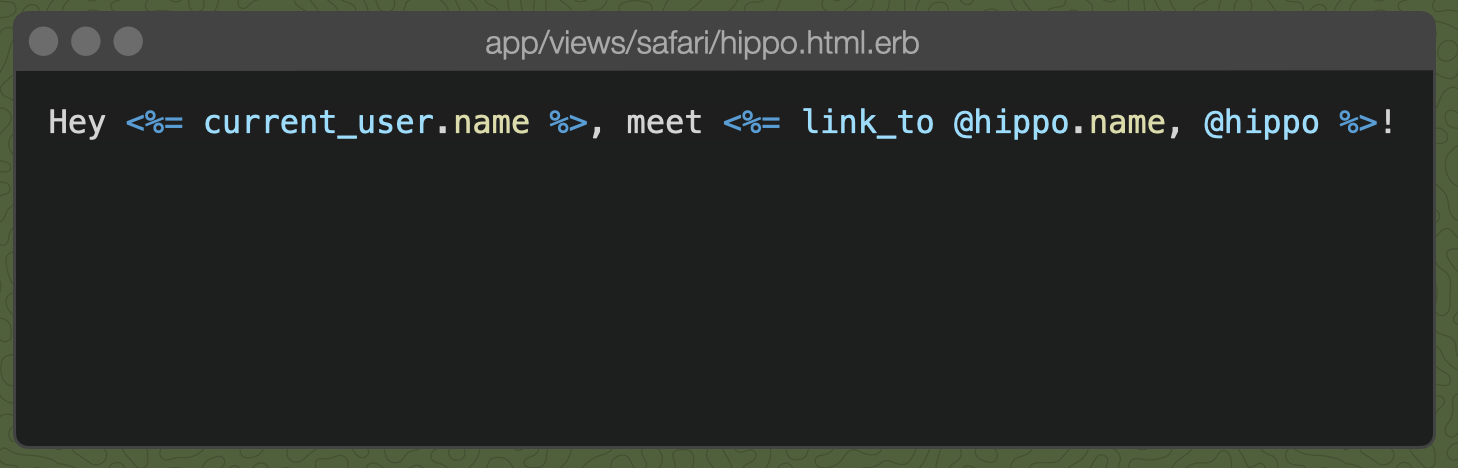
When we visit "skylight.io/find-hippo" and call render :hippo, the render method finds the appropriate template, fills in all of the blanks with our instance variables, then generates the body to send to the browser.
In order to accomplish this, Rails generates a "View Context" class specific to each controller. Here's a very simplified example of what that view context class for the Safari Controller looks like:
class SafariControllerViewContext < ActionView::Base
include Rails::AllTheHelpers
# link_to, etc.
include MyApp::AllTheHelpers
# current_user, etc.
def initialize(assigns)
assigns.each { |k, v| instance_variable_set("@#{k}", v) }
end
private
# Hey <%= current_user.name %>, meet <%= link_to @hippo.name, @hippo %>!
def __compiled_app_templates_hippo_erb
output = ""
output << "Hey "
output << html_escape(current_user.name)
output << ", meet"
output << link_to(html_escape(@hippo.name), @hippo)
output << "!"
output
end
end
(Note: To see the actual code, look in ActionView::Base, ActionView::Rendering, ActionView::Renderer, ActionView::TemplateRenderer, and ActionView::Template.)
When the View Context is initialized, Rails loops through all of the instance variables we have set in our controller (in this case @hippo) and copies them into the view context object for use in the template. These instance variables are known as "assigns."
The View Context class includes all of the helpers available from Action View (such as link_to) and all of the helpers we have defined in our app (such as current_user).
Each template is compiled into an instance method on the View Context class. Essentially, each template's method is a souped up string concatenation. In this case:
- Start the output string with "Hey ".
- Get
self.current_user, which is available because we included all of our app helpers in the View Context class. Escapecurrent_user.namesince it might be user input, then append it to the output string. - Add ", meet".
- Get the
@hippoinstance variable that we set when we initialized the view context. Useself.link_toto generate a link to the page for our hippo. Again,link_tois available because we included all of the Action View helpers as a module. Escape@hippo.nameto use for the link text, then append the link to the output string. - Add the "!" to finish the output string.
- Return the output string.
And put it all together:
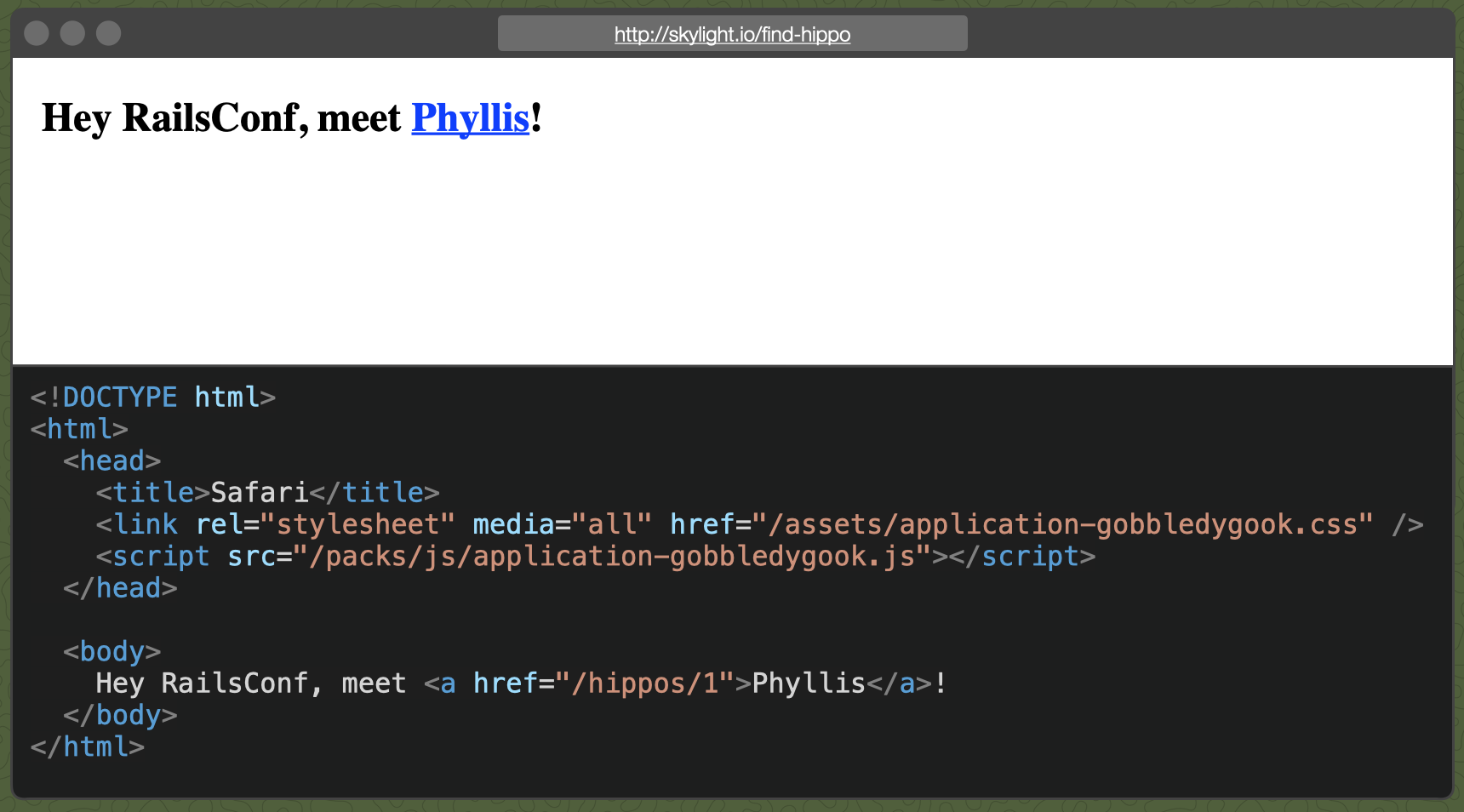
Wow! We've finally found the elusive hippo, Phyllis, and she's 200 OK. Along the way, we've witnessed rare action, unimaginable scale, impossible locations and intimate moments captured from the deepest depths of Rails internals. We've travelled across the great text/plain, taking in the spectacular Action View as we found our way back to the browser.
Thank you for joining me while we unearthed...the amazing lifecycle of a Rails response.