The Lifecycle of a Request
This post is part of a series. Check out Part II: The Lifecycle of a Response here!
This post is a write-up of the talk we gave at RailsConf 2019. You can find the slides here.
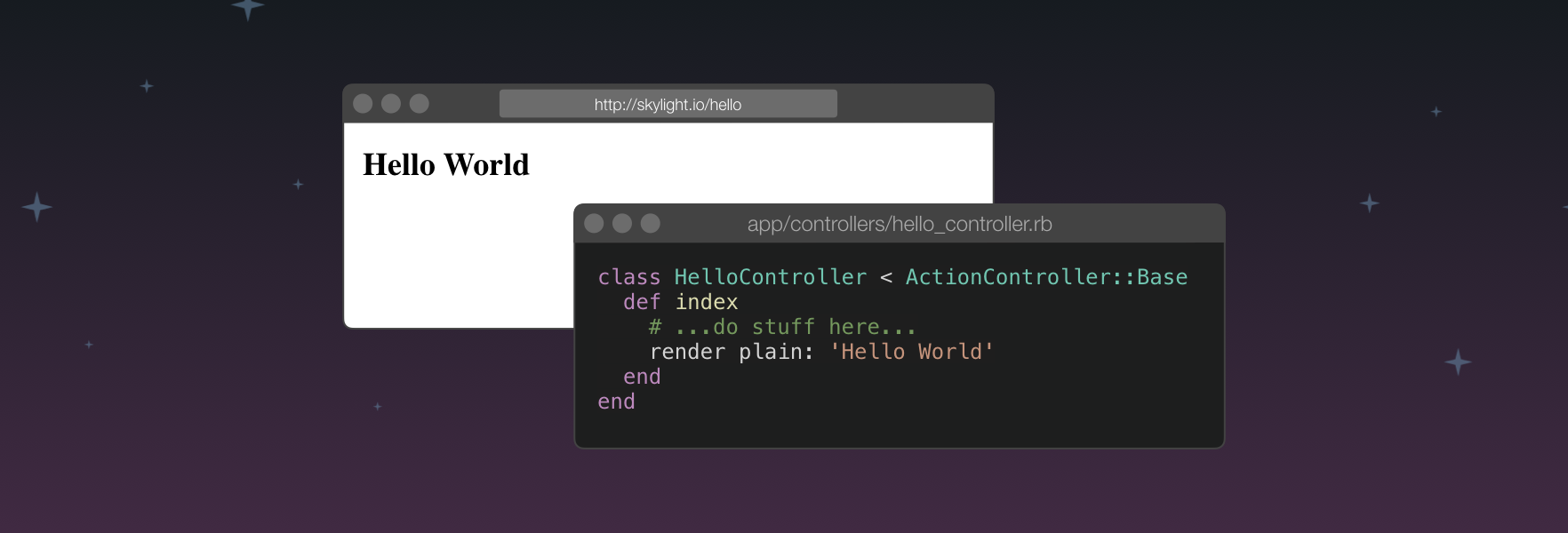
Most Rails developers should be pretty familiar with this work flow: open up a controller file in your editor, write some Ruby code inside an action method, visit that URL from the browser and the code you just wrote comes alive. But have you thought about how any of this works? How did typing a URL into your browser's address bar turn into a method call on your controllers? Who actually calls your methods?
A journey into the Interwebs
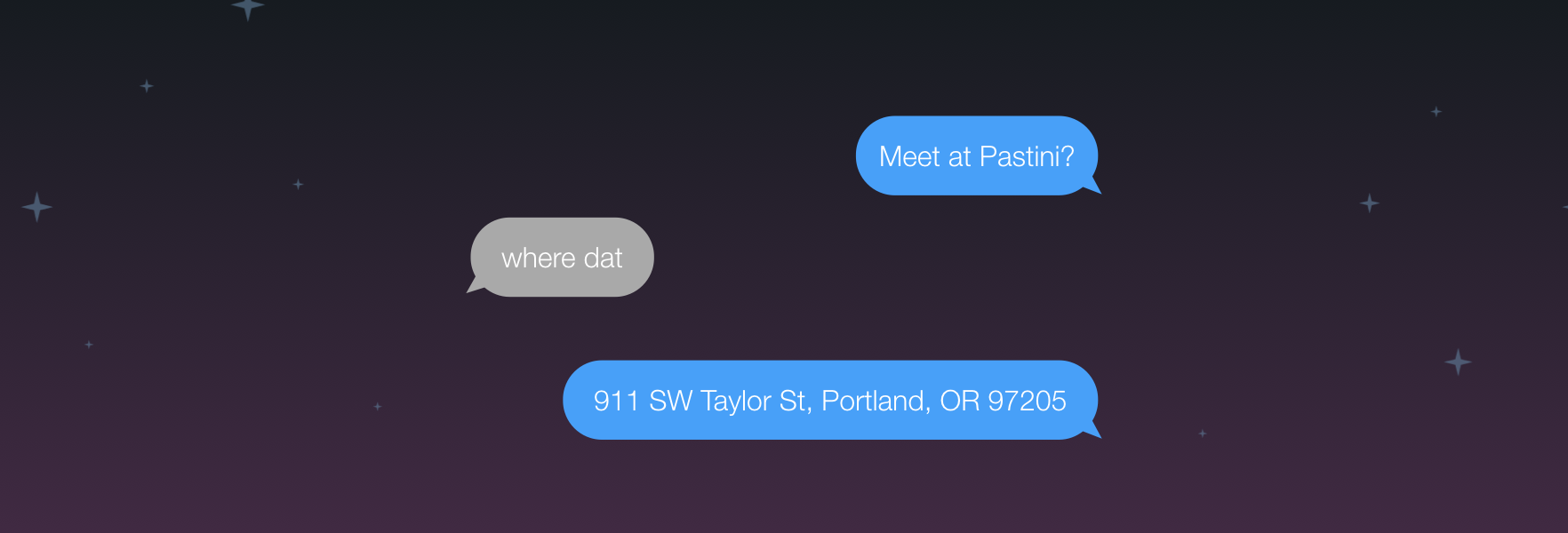
Let's say you are meeting someone for lunch. "Meet at Pastini" probably works for your co-workers who go there a lot, but may not be so helpful for your out-of-town friend. Instead, you should probably provide the street address of the restaurant, that way, they can give it to the cab driver, or just ask a local for directions.
Computers work much the same way. When you type a domain name like that into your browser, the first order of business is for the browser to connect to your server. While domain names like "skylight.io" are easier for us to remember, it doesn't help your computer find your server. To figure out how to get there, they need to translate that name into an address for computer networks, this is the IP address. (It stands for Internet Protocol address, in case you are wondering!)
It looks something like 34.194.84.73, you've probably come across it at some point. With this kind of address, computers can navigate the interconnected networks of the Internet and find their way to their destinations.
DNS, which stands for Domain Name System, is what helps our computers translate the domain name into the IP address they use to find the correct server. You can try it for yourself with a utility called dig on your computer (or with this online version).
; <<>> DiG 9.10.6 <<>> skylight.io
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32689
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;skylight.io. IN A
;; ANSWER SECTION:
skylight.io. 59 IN A 34.194.84.73
;; Query time: 34 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Mon Apr 29 14:50:34 PDT 2019
;; MSG SIZE rcvd: 56
The output looks a bit intimidating, but the main thing to see here is in the answer section, it resolved the "skylight.io" domain into the IP address 34.194.84.73.
The DNS is a registry of domain names mapped to IP addresses
When you buy/own a domain you are in charge of setting up and maintaining this mapping, otherwise, your customers won't be able to find you.
Okay, once we have the IP address of the server, our browser can connect to it. The way that the browser connects to the server is actually pretty interesting, you can think of opening a connection between the two like picking up a phone and dialing someone's number.
In fact, we can try this one too! There is this program on your computer called telnet, that lets you open a "raw" connection to any server. For example, telnet 34.194.84.73 80 would try to open a connection to the server we found earlier, on port 80, which is the default HTTP port.
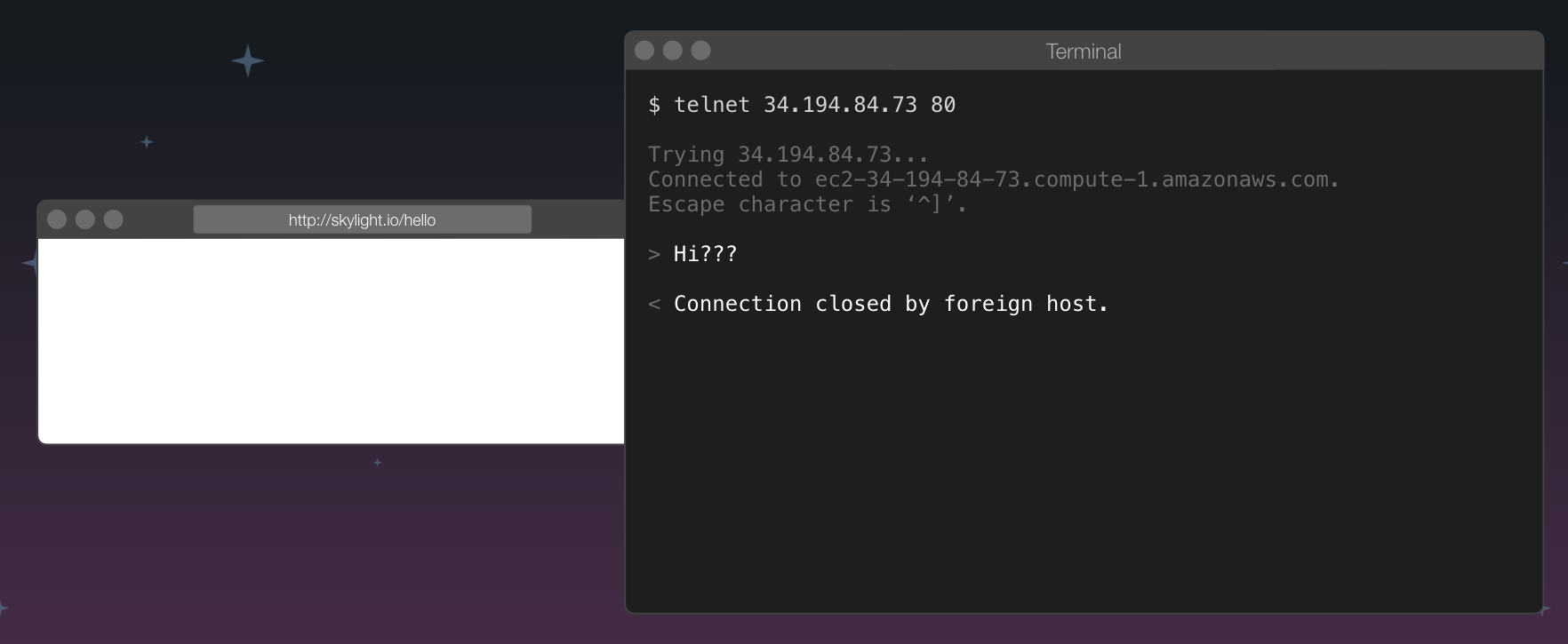
Once we have connected, we have to say something, but what do we say? The browsers and the servers have to agree on a language for "speaking" to each other, so that they can understand what one another is asking for. This is where HTTP comes in; it stands for hyper text transfer protocol, which is the language that both browsers and web servers can understand.
To make the request for "skylight.io/hello", here is the simplest request that we could make. It specifics that it is a GET request, for the path /hello, using the HTTP protocol version 1.1, and it is for the host "skylight.io":
GET /hello HTTP/1.1
Host: skylight.io
If we carefully type this into our telnet session (the trailing new line is important to signify the end of the request), we may get a response from the server that looks like this:
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Length: 11
Date: Thu, 25 Apr 2019 18:52:54 GMT
Hello World
It specified the request was successful, gives a bunch of header information, and finally, "Hello World" – the text we rendered from the controller.
HTTP is a plain-text protocol, as opposed to a binary protocol, which makes it easy for humans to learn, understand and debug. It provides a structured way for the browser to ask for web pages and assets, submit forms, handle caching, compression and other mundane details.
Just like your phone line, the connection between the browser and the server is unencrypted.
The request goes through a lot of places to get to the other side: the conference wifi routers, the convention center's routers, our Internet provider, the server’s hosting company, and many other intermediate networks in between that helped forward the request along to the right place. This means, a lot of parties along the way have the opportunity to eavesdrop in on the conversion. But maybe you don’t want others to know what conversation you’re having?
No problem, you can just encrypt the contents of the conversation. It will still pass through all the same parties, and they will still be able to see that you are sending each other messages. But, those messages won’t make sense to them, because only your browser and the server have the keys to decrypt these messages.
This is known as HTTPS – the S makes it secure ;) Notably, it's not a different protocol from HTTP. You are still speaking in the same plain-text protocol that we saw earlier, but before before the browser sends the message out, it encrypts it, and before the server interprets the message, it decrypts it.
The encryption/decryption is done by using a secret key that both the browser and the server have agreed upon and no one else knows about. But how do the browser and server pick what keys to use for encryption/decryption without giving those keys away while all the other parties are listening in? Well, that's a topic for another time.
The server

By now, your browser has successfully connected to the server and asked it for a specific web page. How did it generate this response?
First of all, what kind of server is this? It’s a "web server", which really just means that it "speaks" HTTP, as we saw earlier. Some examples are apache, nginx, passenger, lighthttpd, unicorn, puma, and even webrick; some are written in Ruby, others are written in system languages like C.
Their job is to parse and "understand" the request, and make a decision on how to service that request. For simple requests, like serving static assets, you can easily just configure the web server to do that for you.
For example, let's say that we want to tell the web server that whenever a browser requests anything under "/assets/", then the web server should try to find that file in my app's "/public/assets" folder. If it exists, it should serve that with compression, otherwise, it should return a 404 not found page.
Depending on which web server you are using, there are specific configuration languages or syntax you might want to use. For example, if you are using nginx, you would probably put something like this in nginx.conf:
location /assets {
alias /var/myapp/public/assets;
gzip_static on;
gzip on;
expires max;
add_header Cache-Control public;
}
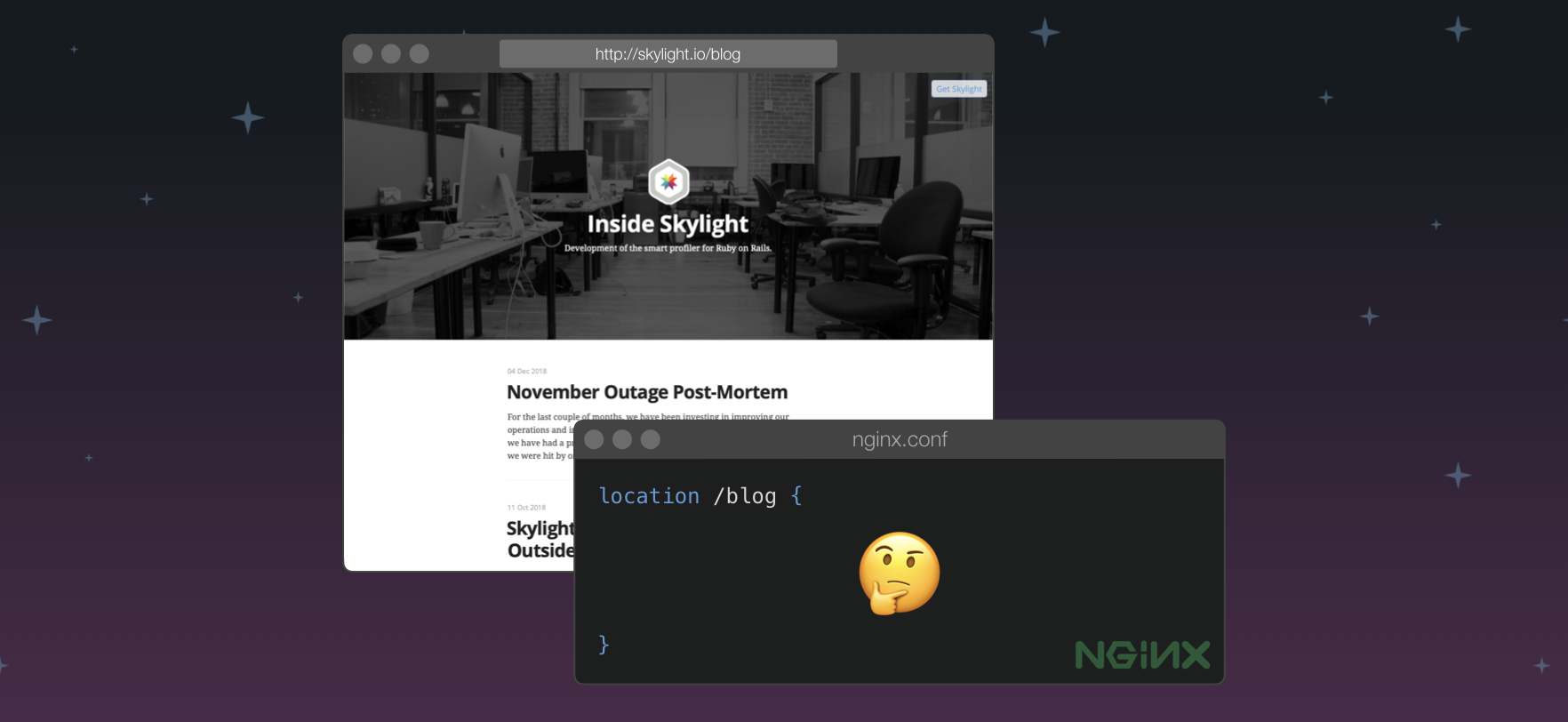
For more complicated things though, it gets trickier.
For example, we might want to tell our web server: "Hey, whenever a browser goes to "/blog", go to the database and get the the 10 most recent blog post, make them look pretty, maybe show some comments too, and throw in a header and footer, a nav bar, some JS and CSS, and off you go!"
Well, this is probably something that's too complicated to express in the web server's configuration language. But hey, that's what we have Rails for. So really, we want to tell the web server that it needs to hand these requests off to Rails for further processing, but how is the web server going to communicate with Rails?
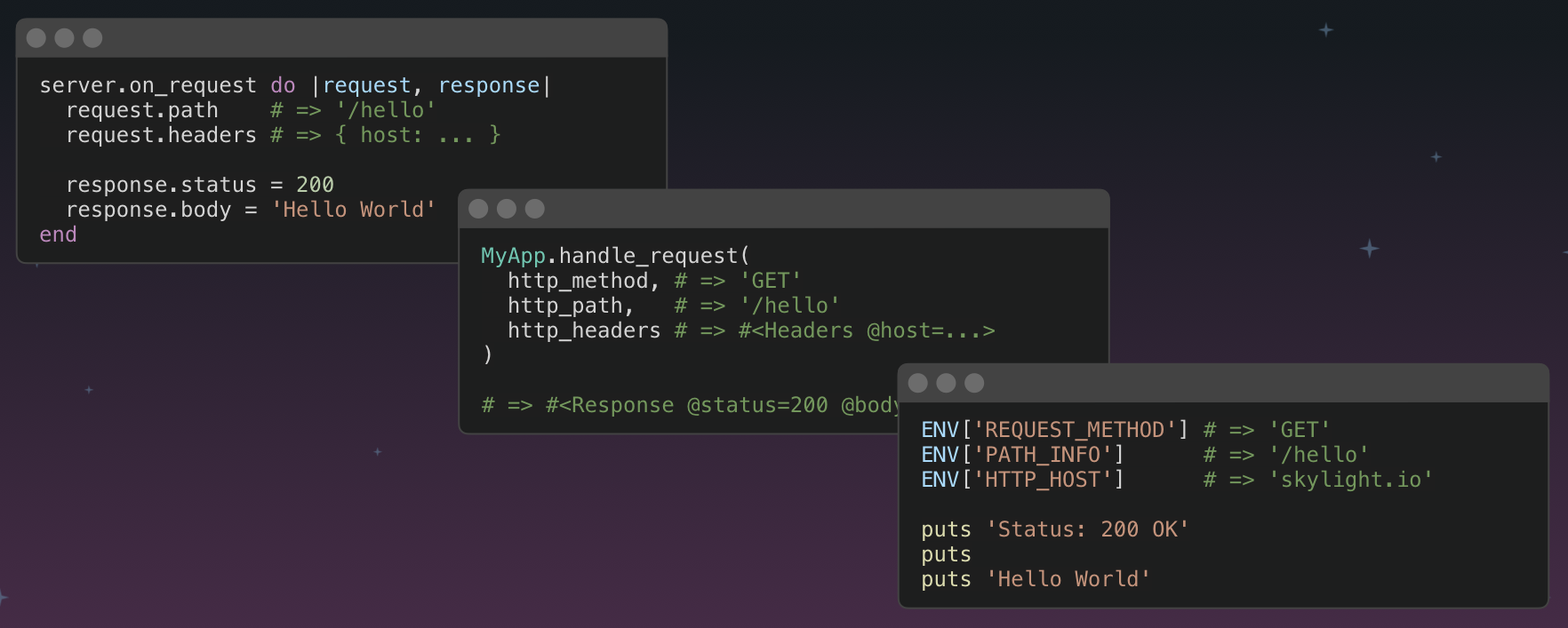
In Ruby, there are many ways to communicate this kind of information. Rails could potentially register a block with the server, or the server could call a method on Rails. The server could pass the request information as method arguments, environment variables, or maybe even global variables? And if we do that, well then, what kind of object should these be? On the flip side, how will Rails communicate back to the web server?
Ultimately, all of these options work, and at the end of the day, which one you pick is not nearly as important as everyone agreeing on the same convention. That's why Rack was born – to present a unified API for web servers to communicate with Ruby web frameworks, and vice versa. By implementing the Rack protocol, all Ruby frameworks that conforms to that convention will work seamlessly with these web servers.
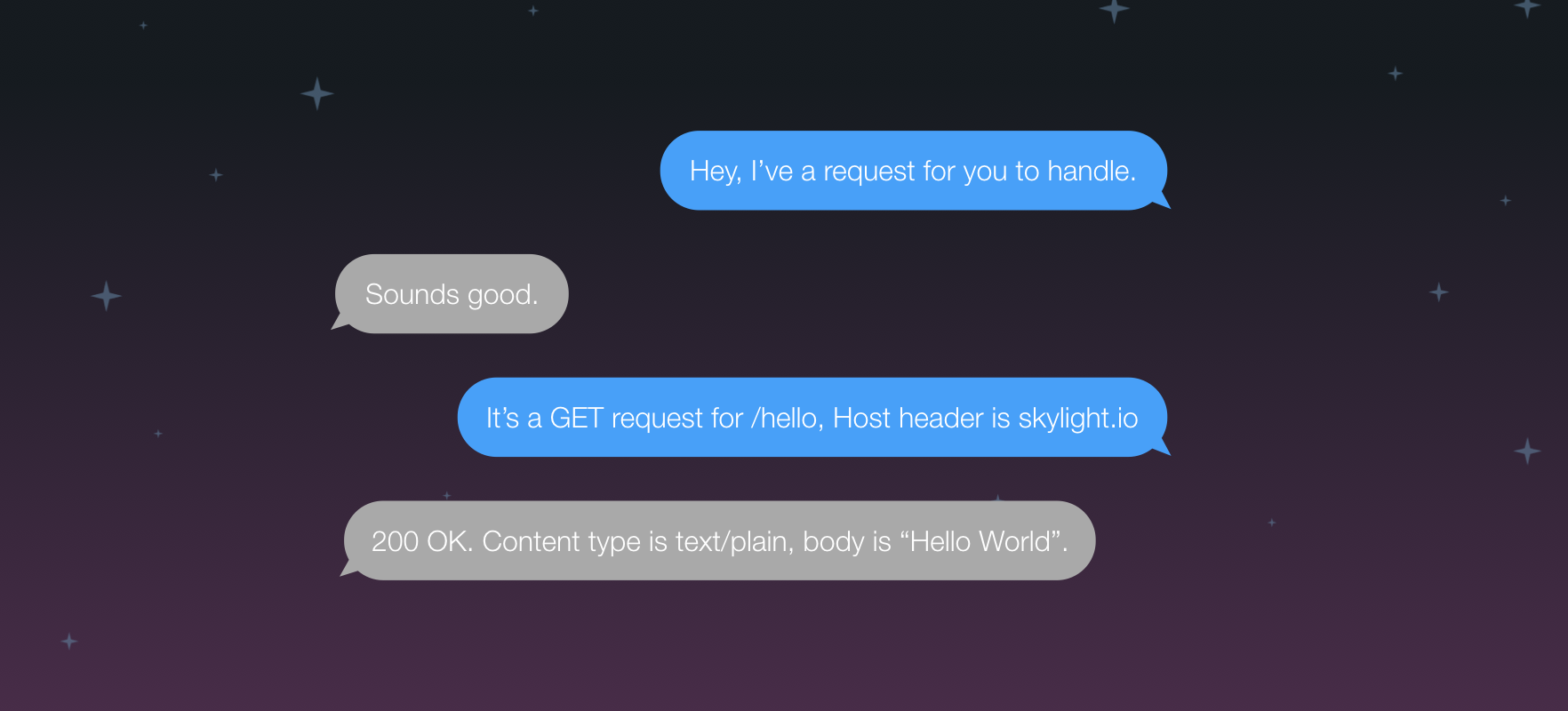
Rack is a simple Ruby protocol/convention that does a few things. The web server needs to tell the web framework, "Hey, here a request for you to handle. By the way, here are the deets for the request: paths, http verb, headers, etc." On the other hand, the framework needs to tell the server, "Hey, that’s cool, I’ve handled it. Here is the result... the status code, headers, and body."
In order to remain lightweight and framework agnostic, Rack picked the simplest possible way to do this in Ruby. It notifies the web framework using a method call, communicates the details as method arguments, and the web framework communicates back by return values from the method call.
In code, that looks like this.
env = {
'REQUEST_METHOD' => 'GET',
'PATH_INFO' => '/hello',
'HTTP_HOST' => 'skylight.io',
# ...
}
status, headers, body = app.call(env)
status # => 200
headers # => { 'Content-Type' => 'text/plain' }
body # => ['Hello World']
First the web server prepares a hash, which is conventionally called the "env hash". The env hash contains all the information from the HTTP request – for example, REQUEST_METHOD contains the HTTP verb, PATH_INFO contains the request path and HTTP_* has the corresponding header values.
On the other hand, the "app" or framework must implement a #call method. The server will expect it to be there and invoke it with the env hash as the only argument. It is expected to handle the request based on the information in the env hash and return an array with exactly three things in it (a.k.a. "a tuple of three").
So what are the three things?
The first element is the HTTP status code – 200 for a successful request, 404 for not found, etc. The second element is a hash containing the response headers, such as Content-Type. The third and final element in the array is the response body. We might think that the body should be a string, but it's actually not! For some technical reasons, the body is an "each-able" object – a object that implements a #each that yields strings. In the simple case, you can just return an array with a single string in it.
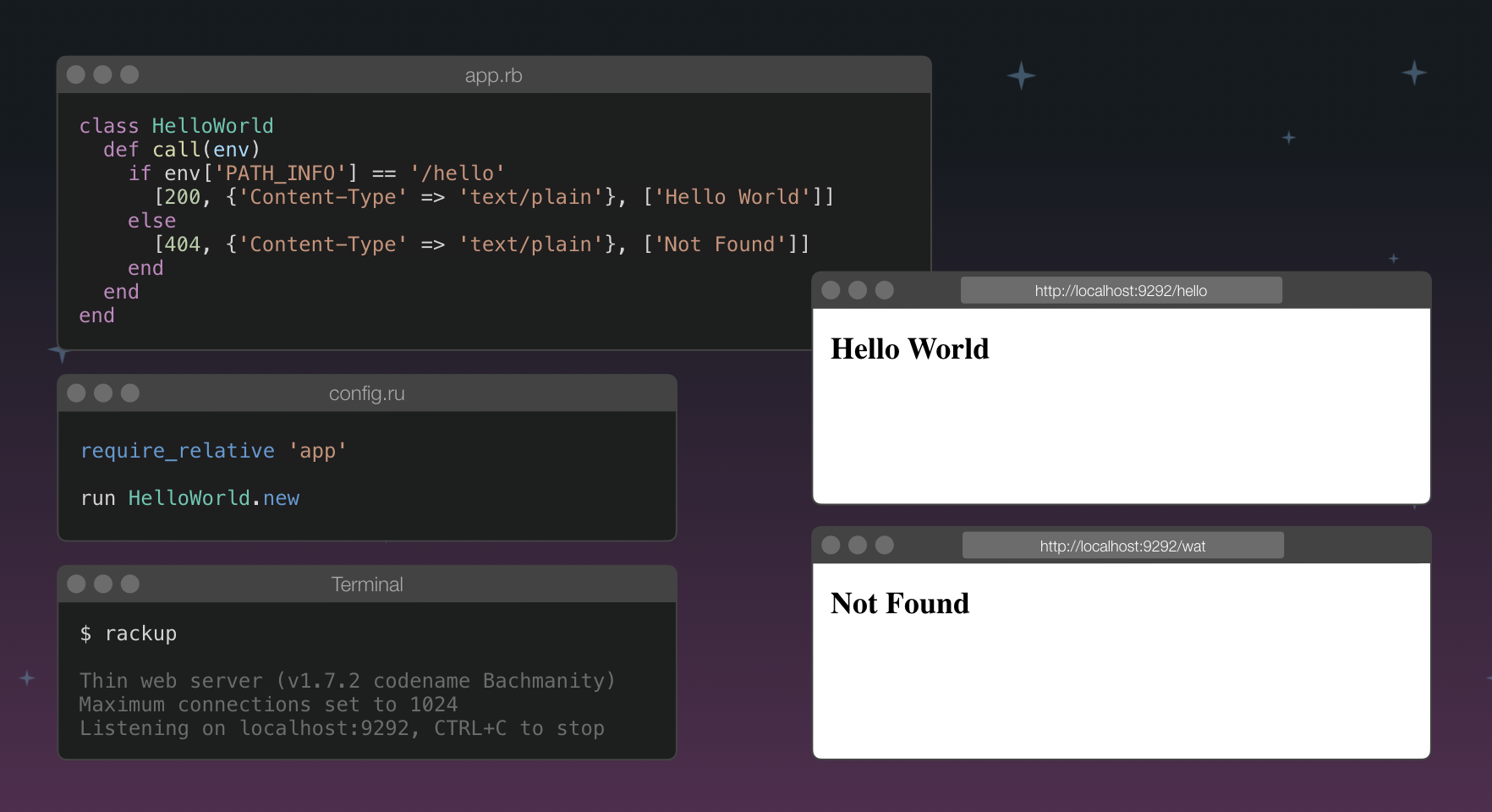
So, let's see this in action! Before we dive into Rails, let's try to build a simple Rack app.
# app.rb
class HelloWorld
def call(env)
if env['PATH_INFO'] == '/hello'
[200, {'Content-Type' => 'text/plain'}, ['Hello World']]
else
[404, {'Content-Type' => 'text/plain'}, ['Not Found']]
end
end
end
This is probably the simplest Rack app that we could build. It didn't have to subclass from anything, just a simple class that implements #call. It looks at the request path from the env hash, if it matches /hello exactly, it renders a plain text "Hello World" response, otherwise, it renders a 404 "Not Found" error response.
Alright, now that we have written our app, how do we use it? How do we make it do things? Recall that Rack is only a protocol that web servers can implement, so we will need to wire up our app to a Rack-aware web server.
Conveniently, the rack gem, a collection of complimentary utilities for implementing and using the Rack specification, comes with an example web server called rackup that can do this for us. rackup understands a config file format called config.ru:
# config.ru
require_relative 'app'
run HelloWorld.new
This is basically a Ruby file with some extra configuration DSL. Here we are requiring our app file, constructing an instance of our HelloWorld app and passing it to the rackup server using the run DSL method.
With that, we can run the rackup command from within the directory of our config.ru file and it'll attach the server to port 9292 by default. If we visit http://localhost:9292/hello, we will see "Hello World", and if we navigate to http://localhost:9292/wat we will see the "Not Found" error.
Now, let's say we want to add a redirect from the root path http://localhost:9292/ to http://localhost:9292/hello. We can modify our app like so:
# app.rb
class HelloWorld
def call(env)
if env['PATH_INFO'] == '/'
[301, {'Location' => '/hello'}, []]
elsif env['PATH_INFO'] == '/hello'
[200, {'Content-Type' => 'text/plain'}, ['Hello World']]
else
[404, {'Content-Type' => 'text/plain'}, ['Not Found']]
end
end
end
This works, but it doesn't scale very far. If we keep adding things here, this if/elsif/else/end chaing is going to get very long. Redirecting is also a pretty common thing that we may want to reuse in different parts of our application. Wouldn't it be great if we can implement this functionality in a modular, reusable and composable manner?
Of course we can!
# app.rb
class Redirect
def initialize(app, from:, to:)
@app = app
@from = from
@to = to
end
def call(env)
if env["PATH_INFO"] == @from
[301, {"Location" => @to}, []]
else
@app.call(env)
end
end
end
class HelloWorld
def call(env)
if env["PATH_INFO"] == '/hello'
[200, {"Content-Type" => "text/plain"}, ["Hello World!"]]
else
[404, {"Content-Type" => "text/plain"}, ["Not Found!"]]
end
end
end
Here, we are able to keep HelloWorld exactly the way it was before. Instead, we added a new Redirect class that is responsible for manging that one single responsibility. If it found a matching path, it will issue a redirect response and that would be the end. If it didn't, it delegates to the next app that we passed to it.
To wire this up, we change our config.ru like so:
require_relative 'app'
run Redirect.new(
HelloWorld.new,
from: '/',
to: '/hello'
)
We constructed an instance of the HelloWorld app and passed it to the Redirect app.
With this, we have implemented a Rack middleware! Middlewares are not technically part of the Rack spec – as far as the web server is concerned, there is only one app (Redirect), it just happens to call another Rack app as part of it's #call method, but the web server doesn't need to know that.
This middleware pattern is so common that config.ru has a dedicated DSL keyword for it:
require_relative 'app'
use Redirect, from: '/', to: '/hello'
run HelloWorld.new
With the use keyword, we can clean up the nesting. Neato!
The middleware pattern is very poweful. Without writing any extra code, we can beef up our toy app to add compression, HTTP caching and handle HEAD requests just by adding a few middleware from the rack gem:
require_relative 'app'
use Rack::Deflater
use Rack::Head
use Rack::ConditionalGet
use Rack::ETag
use Redirect, from: '/', to: '/hello'
run HelloWorld.new
You can imagine building up a very functional app this way.
Rails <3 Rack
Finally, we are ready for Rails!
Of course, Rails implements Rack. If you look at your Rails app, it should come with a config.ru file that looks like this:
require_relative 'config/environment'
run Rails.application
Even though config.ru originated from rackup, it is also understood by a few other web servers and services like Heroku, so it's useful for Rails to include it by default.
We learned that we are supposed to pass a Rack app to the run keyword, so Rails.application must be a Rack app that responds to #call! Well, why don't we try it from the Rails console!
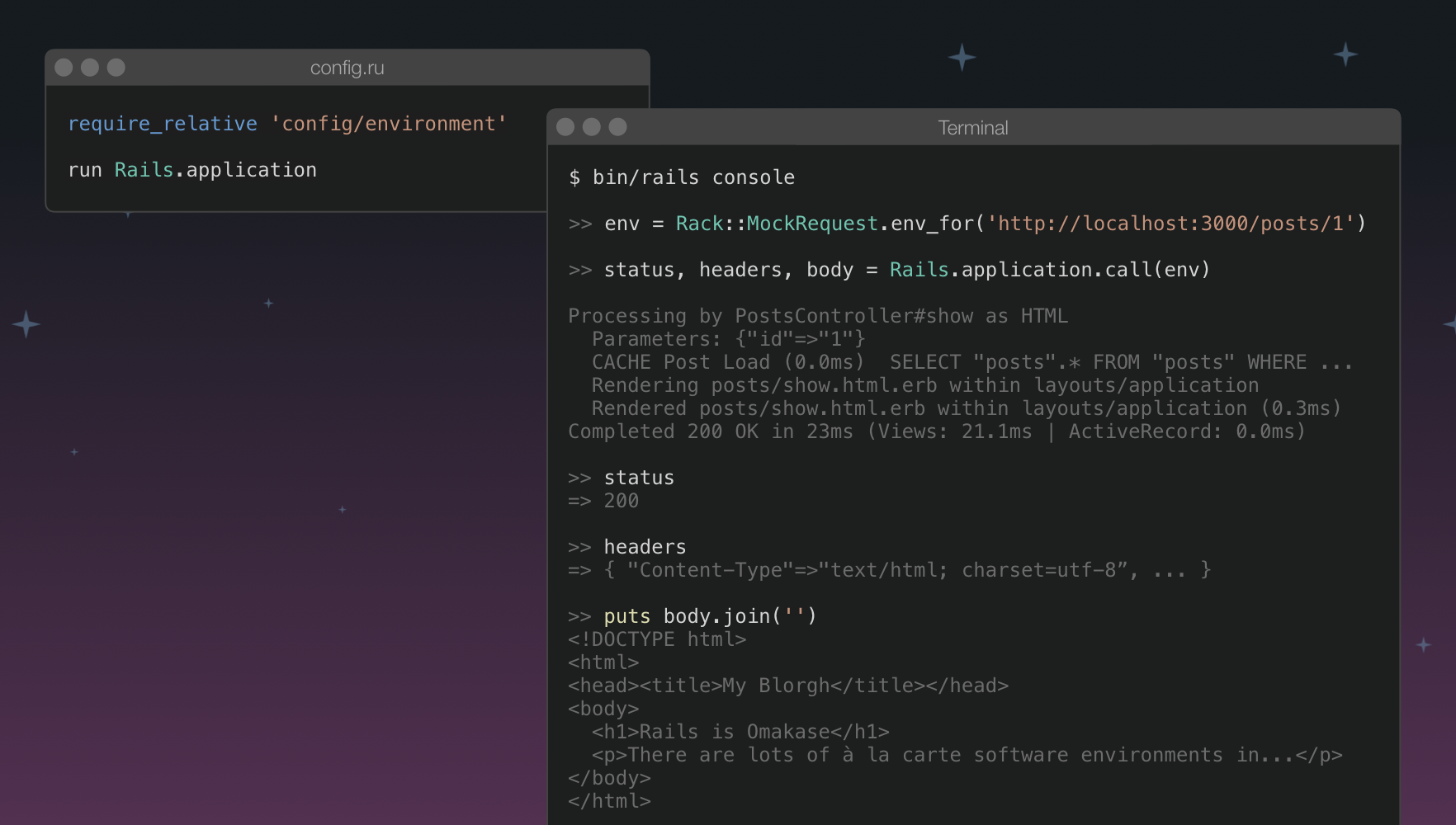
Instead of building a spec-complient env hash by hand, we can use the Rack::MockRequest.env_for utility method from the rack gem. It takes a URL and takes care of the rest for you. Calling Rails.application.call with this env hash yields the expected tuple of status code, headers and body. It even prints the familiar request log to the console. Cool!
One thing that stands out from the config.ru file in our Rails app is that it didn't have any use statements. Does Rails not use any middlewares? No! In fact, there is a handy command that you can run to see all the middlewares in your app using the familiar config.ru syntax:
$ bin/rails middleware
use Rack::Sendfile
use ActionDispatch::Executor
use ActiveSupport::Cache::Strategy::LocalCache::Middleware
use Rack::Runtime
use Rack::MethodOverride
use ActionDispatch::RequestId
use ActionDispatch::RemoteIp
use Rails::Rack::Logger
use ActionDispatch::ShowExceptions
use ActionDispatch::DebugExceptions
use ActionDispatch::Callbacks
use ActionDispatch::Cookies
use ActionDispatch::Session::CookieStore
use ActionDispatch::Flash
use ActionDispatch::ContentSecurityPolicy::Middleware
use Rack::Head
use Rack::ConditionalGet
use Rack::ETag
use Rack::TempfileReaper
run Blorgh::Application.routes
We can see that Rails has implemented a lot of its functionalitiy in middlewares, such as cookies handling. This is cool, because if we are implementing an API server, we can just remove these unnecessary middlewares. But how?
Recall that use statement is just a convenience in for building up your app in config.ru, the web server only "sees" the outer-most app anyway. Rails have a different convenience for manging middlewares in config/application.rb:
# config/application.rb
require_relative 'boot'
require 'rails/all'
Bundler.require(*Rails.groups)
module Blorgh
class Application < Rails::Application
# Disable cookies
config.middleware.delete ActionDispatch::Cookies
config.middleware.delete ActionDispatch::Session::CookieStore
config.middleware.delete ActionDispatch::Flash
# Add your own middleware
config.middleware.use CaptchaEverywhere
end
end
Finally, our app!
So, we looked at the middlewares, but where's our "app"? From the output of bin/rails middleware, we know that use is for middlewares and run is for the app, so Blorgh::Application.routes must be it!
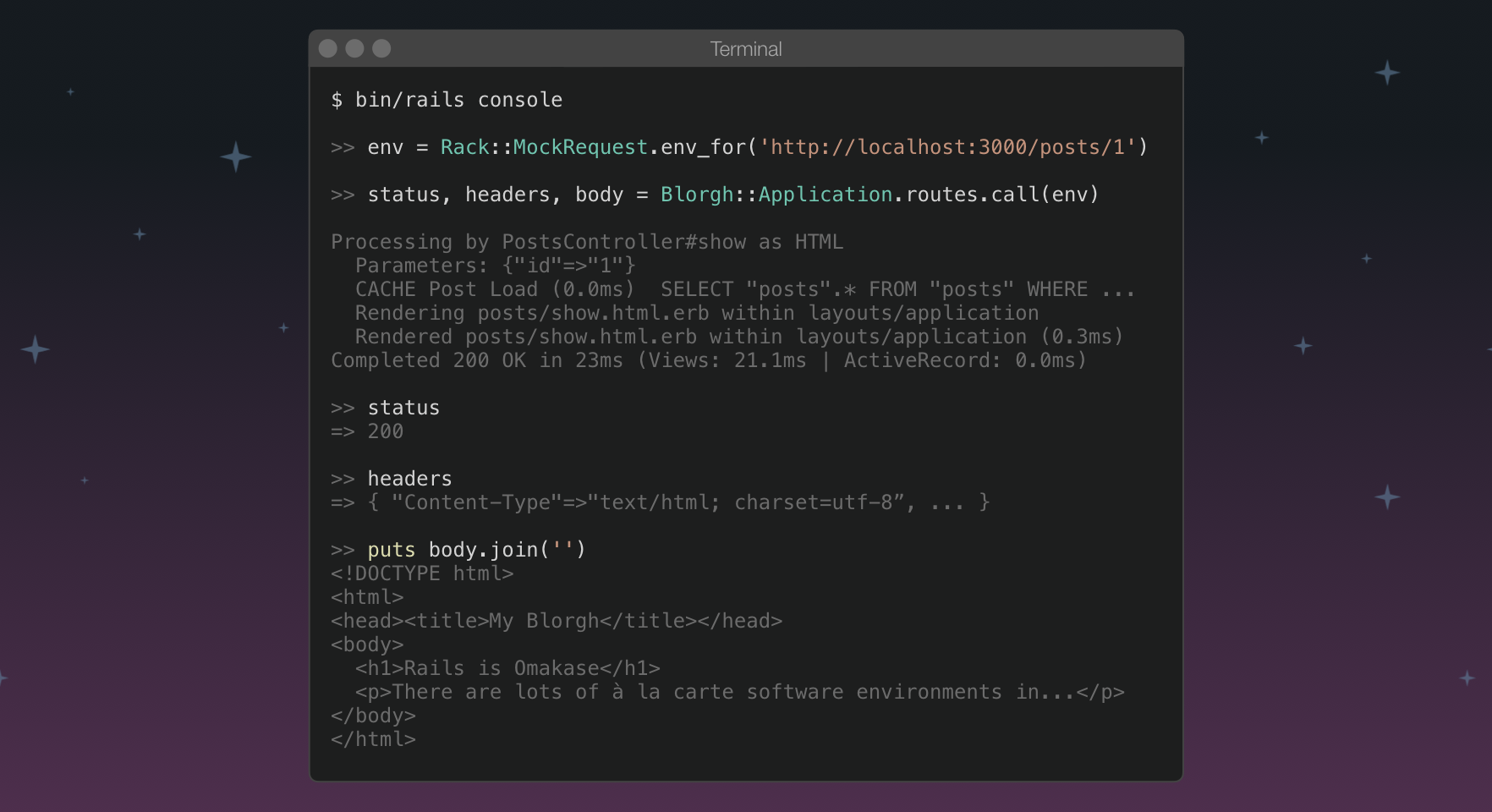
Running the same test in the Rails console, we can see that if we replace Rails.application.call with Blorgh::Application.routes, everything still works. So what does this rack app do, and where did it come from?
This Rack app looks at the request URL, match it against a bunch of routing rules to find the right controller/action to call. Rails generates this app for you by Rails based on your config/routes.rb.
# config/routes.rb
Rails.application.routes.draw do
resources :posts
end
The resources DSL should look pretty familiar to most Rails developers. It's a shorthand for defining a bunch of routes at once. Ultimately, it expands into these seven routes:
# config/routes.rb
Rails.application.routes.draw do
# resources :posts becomes...
get '/posts' => 'posts#index'
get '/posts/new' => 'posts#new'
post '/posts' => 'posts#create'
get '/posts/:id' => 'posts#show'
get '/posts/:id/edit' => 'posts#edit'
put '/posts/:id' => 'posts#update'
delete '/posts/:id' => 'posts#destroy'
end
For example, when you make a GET request to /posts, it will call the PostsController#index method, if you make a PUT request to /posts/:id, it will go to PostsController#update instead.
So, what is this posts#index string? Well, we know it stands for the index action on the PostsController. If you follow the code in Rails, you will see that it eventually expands into PostsController.action(:index). So what is that?
Here is a much simplified version of the Action Controller code:
class ActionController::Base
def self.action(name)
->(env) {
request = ActionDispatch::Request.new(env)
response = ActionDispatch::Response.new(request)
controller = self.new(request, response)
controller.process_action(name)
response.to_a
}
end
attr_reader :request, :response, :params
def initialize(request, response)
@request = request
@response = response
@params = request.params
end
def process_action(name)
event = 'process_action.action_controller'
payload = {
controller: self.class.name,
action: action_name,
# ...
}
ActiveSupport::Notifications.instrument(event, payload) do
self.send(name)
end
end
end
We see our action class method on the top there. You can see that it returns a lambda. The lambda takes an argument called env. What’s that?
SURPRISE It’s a hash! And what does the lambda return? An array! And by the way, SURPRISE lambdas respond to #call! Yup, it’s a Rack app! Everything is a Rack app!
Finally, putting everything together, you can imagine the routes app is a rack app that looks something like this:
class BlorghRoutes
def call(env)
verb = env['REQUEST_METHOD']
path = env['PATH_INFO']
if verb == 'GET' && path == '/posts'
PostsController.action(:index).call(env)
elsif verb == 'GET' && path == '/posts/new'
PostsController.action(:new).call(env)
elsif verb == 'POST' && path == '/posts'
PostsController.action(:create).call(env)
elsif verb == 'GET' && path =~ %r(/posts/.+)
PostsController.action(:show).call(env)
elsif verb == 'GET' && path =~ %r(/posts/.+/edit)
PostsController.action(:edit).call(env)
elsif verb == 'PUT' && path =~ %r(/posts)
PostsController.action(:update).call(env)
elsif verb == 'DELETE' && path = %r(/posts/.+)
PostsController.action(:destroy).call(env)
else
[404, {'Content-Type': 'text-plain', ...}, ['Not Found!']]
end
end
end
It matches the given request path and http verb against the rules defined in your routes config, and delegates to the appropriate Rack app on the controllers. Good thing you don't have to write this by hand. Thanks Rails!
Now you might be wondering, how does Rails generate this from your routes config to do this mapping, and route every request efficiently? SURPRISE! There's a talk for that, too. Check out Vaidehi's talk from last year's RailsConf.
Ok, now that we know #everythingisarackapp, we can mix and match things. Here are some Pro Tips™:
-
Did you know that you can route a part of your Rails app to a Rack app, just like that?
Rails.application.routes.draw do get '/hello' => HelloWorld.new end -
In fact, now that we learned about lambdas, we can even write that inline!
Rails.application.routes.draw do get '/hello' => ->(env) { [200, {'Content-Type': 'text/plain'}, ['Hello World!'] } end -
You may think that's a terrible idea, but in fact you've probably used this functionality before – how did you think the router's
redirectDSL works? SURPRISE, it returns a rack app!Rails.application.routes.draw do # redirect(...) returns a Rack app! get '/' => redirect('/hello') end -
You can even mount a Sinatra app inside a Rails app! You may not know this, but the Sidekiq web UI
iswas written in Sinatra, so you may already have a Sinatra app running inside your Rails app!Rails.application.routes.draw do mount Sidekiq::Web, at: '/sidekiq' endUpdate: Since Sidekiq 4.2, the web UI was migrated to a custom framework to reduce external dependencies. Of course, it still uses the Rack protocol!
The migration pull request makes for an interesting case study of what it takes to build a minimal version of Sinatra on top of what we learned here about the Rack protocol. Among other things, it handles basic routing, view rendering, redirects and more.
-
Of course, you can also go the other way around an mount your Rails app inside a Sinatra app. We'll leave that up to your imagination.
With what we learned, we can even replace the controller#action string with this:
Rails.application.routes.draw do
get '/posts' => PostsController.action(:index)
get '/posts/new' => PostsController.action(:new)
post '/posts' => PostsController.action(:create)
get '/posts/:id' => PostsController.action(:show)
get '/posts/:id/edit' => PostsController.action(:edit)
put '/posts/:id' => PostsController.action(:update)
delete '/posts/:id' => PostsController.action(:destroy)
end
...or we can paste the output of bin/rails middleware into our config.ru file!
Now, we wouldn't recommend actually doing either of those in your Rails app – it bypasses autoload and some performance optimizations, prevents gems from adding middlewares, is hostile to future changes in Rails, etc. Nevertheless, it's very cool to know how everything fits together!
After all that, now we've finally made it back into the controller action that we started with. But wait, how does render plain... get turned into the response tuple required by the Rack spec? Well, we don't have time for that today, but maybe stay tuned for a "The Lifecycle of a Rails Response" talk/blog post!
How does Skylight work?
What we learned so far is that frameworks aren't magic. They're just a layer of sugar on top of a consistent, well-defined primitive. Conventions help you learn how to use Rails and share your skills with other developers, but on top of that, they give the community the ability to write tools that everyone can share.
For example, Skylight needs to measure how long your entire request took. What better way to do that than a middleware?
$ bin/rails middleware
use Skylight::Middleware
use Rack::Sendfile
use ActionDispatch::Executor
...
run Blorgh::Application.routes
Convention over configuration is also more than just how you build Rails apps. Rails conventions allow Skylight to collect detailed information about your web app without needing a line of Skylight configuration.
Earlier on, we looked at how Rails dispatches actions, in the simplified version of ActionController::Base#process_action. Inside that method, when Rails dispatches actions to your controller method, it uses a built-in instrumentation system called ActiveSupport::Notifications to notify libraries like Skylight that something interesting has happened. This API is how Skylight gets the name of your endpoint without any configuration.
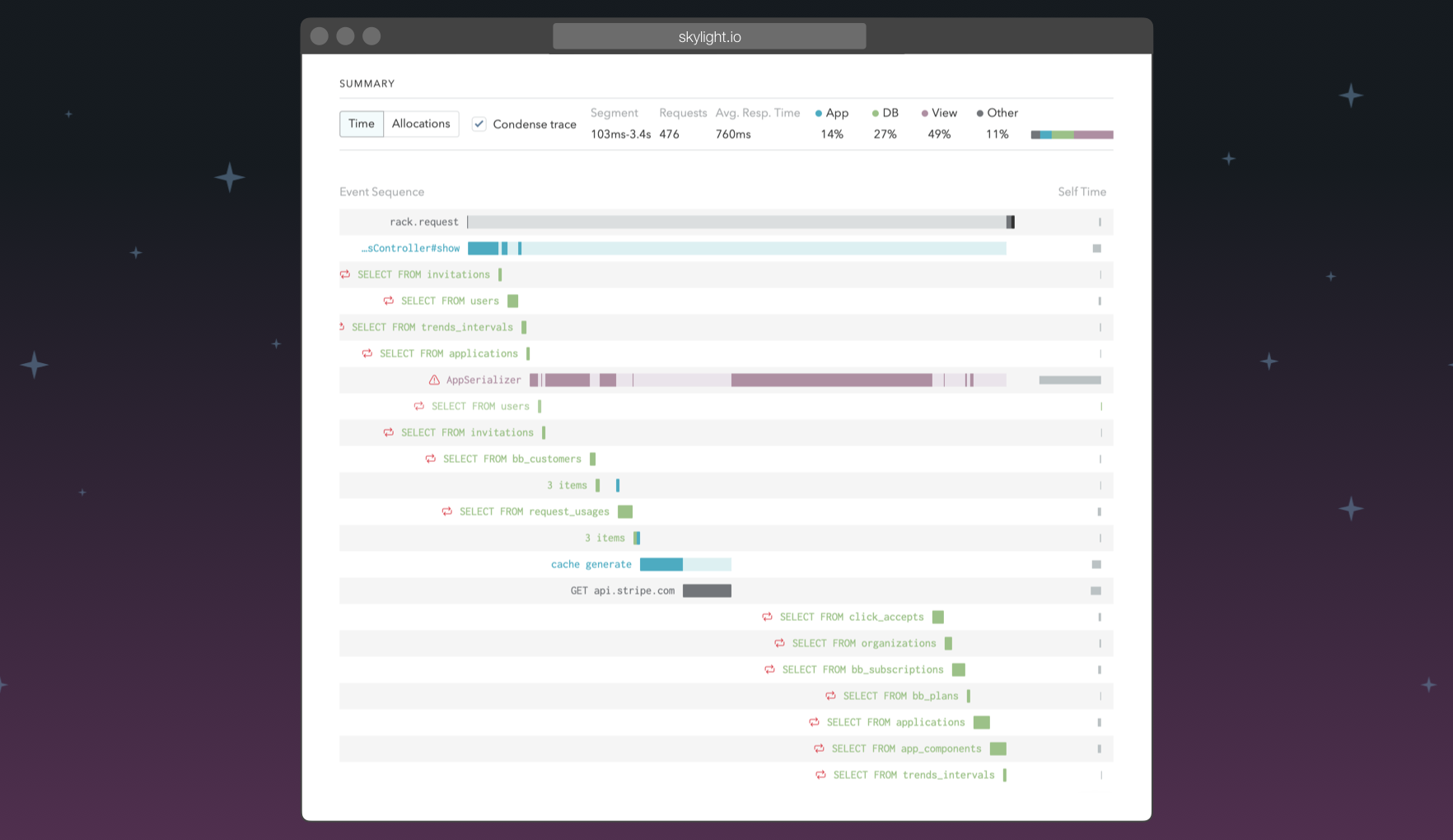
Skylight does way more than give you average response times. We give you a detailed aggregate view of your entire request. We leverage ActiveSupport::Notifications and community conventions to provide conventional descriptions not only for Rails things like template rendering and Active Record timing, but also for popular HTTP libraries, caching libraries, and alternative database libraries (like Mongoid).
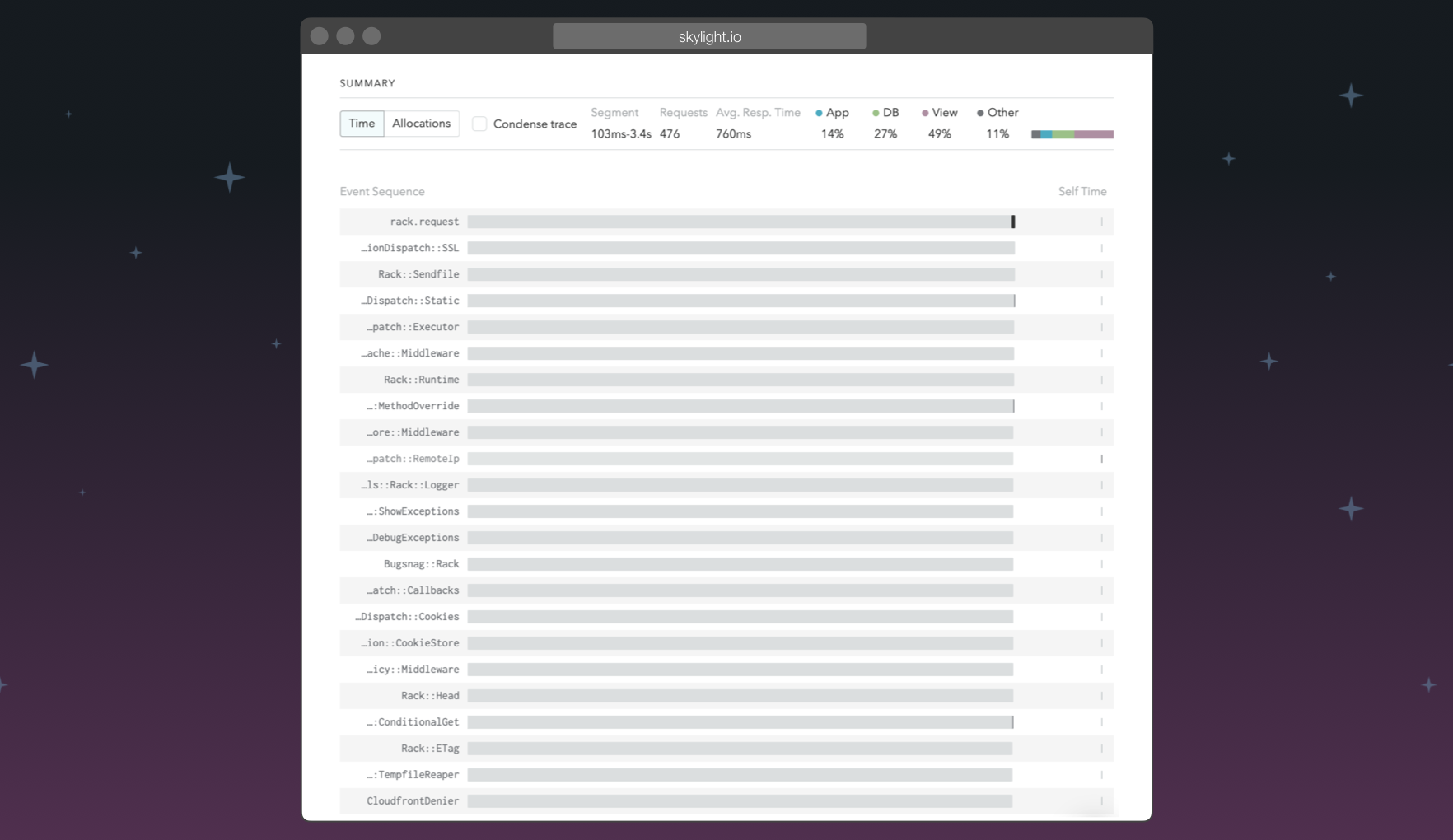
By default, we only show you important parts of your request, so you can focus on speeding up what matters. In this example, you should probably focus on AppSerializer if you want to speed up this endpoint. But we still collect lots more information that you can see if you want to dig in, including all of the Rack middleware used by your app.
This talk is part of a series. Check out The Lifecycle of a Response!