Announcing Skylight 4.0: Now with Background Jobs!
Skylight’s new Background Jobs feature helps you discover and correct hidden performance issues in your Sidekiq, Delayed::Job, and Active Job queues. Now available with the 4.0 Skylight agent.
While Skylight was originally developed to instrument web requests, we understand the web interface is only one part of your server-side application. For this reason, we've been hard at work preparing Skylight for Background Jobs!
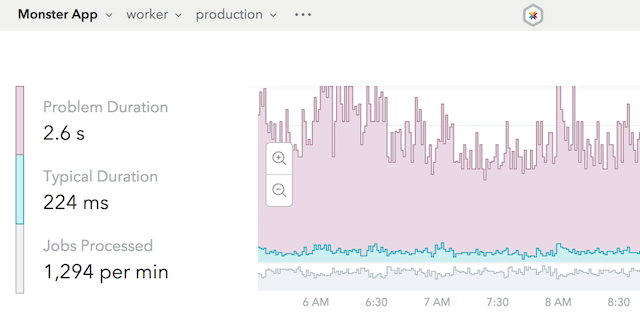
This release is the culmination of over a year of work that touched every part of the Skylight ecosystem and was the motivation behind many of the features and improvements we've released over the past several months. Thank you to all of the Skylight Insiders who tried our the alpha and beta versions; your feedback, as always, was invaluable in preparing this release. We're excited to make Skylight 4.0 with background jobs available to all of our customers!
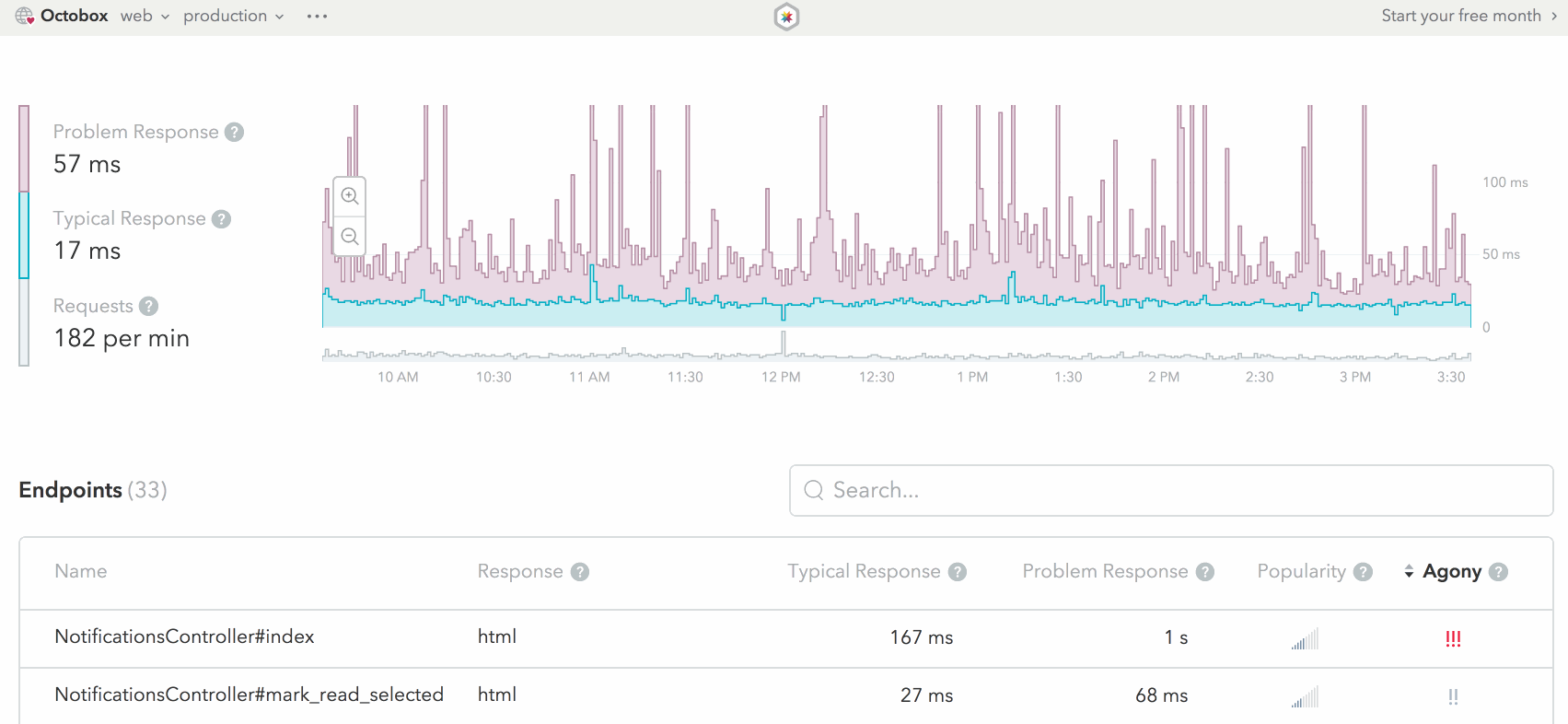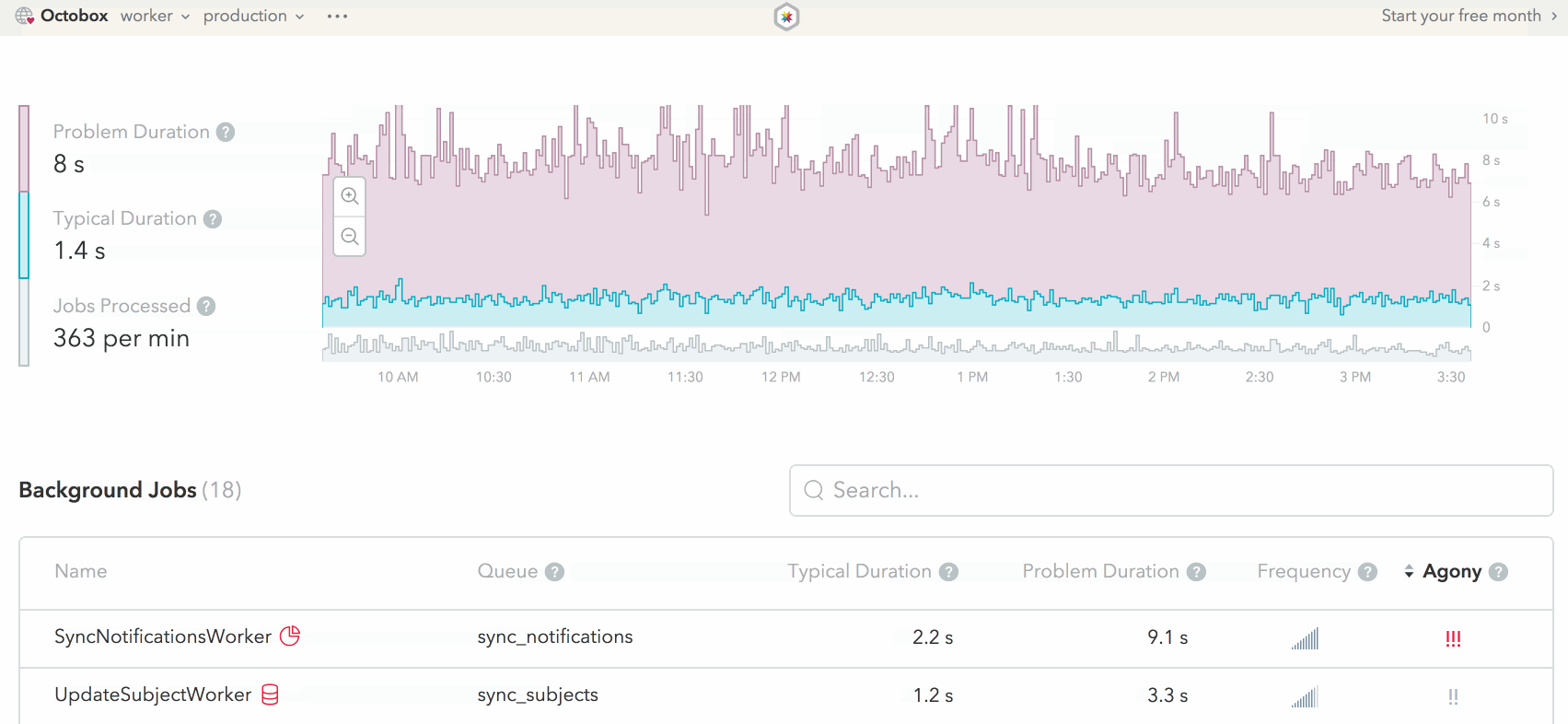
See Skylight for Background Jobs in action on one of our Skylight for Open Source apps: Octobox!
Neato! How do I turn it on? 🎉
Head on over to our background jobs documentation to get started!
Wait…I have questions. 🤔
No worries, we have answers! Read on to learn more about background jobs, why you need them, and how the team at Skylight went about implementing this new feature.
Why should I use background jobs?
We recommend moving slow code, such as third-party integrations, into background jobs in our Performance Tips documentation.
A typical web request finishes within a few seconds, with outliers ranging from dozens of seconds to perhaps a few minutes. Moving time-intensive work to the background—to be executed out-of-band of the typical request-response cycle—eliminates the pipeline coupling the work to the receiver.
For example, the story of user sign-up may differ significantly depending on which side of the looking glass you are on.
🔍 From the user’s point of view, it’s a pretty simple story: “As a user, I want to fill in my email and password, and then get started doing whatever it was I came here to do.” Easy peasy, right?
🔎 From the server’s point of view, there are many events that need to happen: syncing external accounts, setting up various pieces of internal data, mirroring the new account to a CRM, sending a confirmation email, etc. Whew…that might take a while!
These events are all important parts of the site’s functionality but would make the simple action of “signing up” appear unreasonably slow to the user. Not only could this be a bad first experience for the user, but it also risks locking up our web server or timing out the connection. Yikes! 😭
Luckily, developers have background jobs at our disposal. Each one of those events can be considered a separate piece of work, so when a new user signs up, we can tell our jobs processor to handle anything that is not immediately required to redirect the user to the post-sign-up experience. Not only does this allow a much faster response, it frees our web server to handle other traffic, and hopefully makes our user happy. 👍
Why should I track my background jobs’ performance?
While moving work into background jobs helps us improve web request response times, in terms of computing resources, we haven't achieved much else. We still need to do the same amount of work, plus some additional overhead (for example, whatever is necessary to power the background jobs framework itself).
This often means a new cluster of servers. 💸💸💸
Additionally, jobs can put even more load on the database, as we'll probably need to load some of the same records over and over again for each additional job we enqueue.
So while refactoring slow controller endpoints into background jobs may be a big win for your users, you still need to be aware of background application performance because it can have a big impact on your overall system performance. We developed Skylight for Background Jobs for precisely this reason—while jobs performance improvements may be less visible to your customers, we feel that they are just as important for maintaining your overall application health.
How the heck did you pull this off?
As mentioned above, implementation of Skylight for Background Jobs took over a year, with many detours along the way. For part one of this saga, see our post about Skylight Environments implementation, which was actually the first feature on the path to support jobs. After releasing Skylight Environments, we still had a lot of work to do. Here’s the rest of the story of Skylight for Background Jobs as told by Zach, who worked on the feature from start to finish.
The Collector
Skylight was originally designed to instrument and aggregate web request traces, so many of our time-series aggregation algorithms were optimized for data that fit certain criteria.
For example, we assumed that five minutes was a good theoretical maximum span duration, as most web servers include a default timeout well below this value. As it's pretty typical for most requests to finish within a few seconds, a five minute limit should be more than sufficient to handle even the grossest outliers…until now. It's not unusual for a single job to take several minutes or even hours, making our five-minute limit somewhat quaint.
Skylight's data collector is a large Java app ☕️ that accepts transaction-level trace data from all of the Skylight agents in the wild and emits aggregate traces to our UI on skylight.io/app. These aggregate traces track the distributions of the time spent in each transaction, with further aggregation done at the level of individual nodes within the trace. The aggregation and compression of these traces is what allows Skylight to store and query huge amounts of data efficiently, and had been tuned to handle traces of five minutes or less.
Last fall, Godfrey and I set about reading and learning about all of the bespoke digest algorithms and their associated data structures (neither of us had a hand in creating the original app), with the goal of increasing that five minute limit. (Have a look at our November outage post-mortem to get an idea of the operational concerns we need to consider when making these sorts of changes.)
After a few false starts and theoretical model revisions, we successfully increased our max span duration first to one hour, then to four hours (where we currently are). We're still hoping to increase this limit further, but first we want to focus on increasing the number of allowed child spans first to allow for greater fidelity in very long traces.
The Agent
Internally, Skylight has been measuring our own background jobs since late 2017, using an open-source community gem called sidekiq-skylight. A few months later, Peter started working on built-in support for Sidekiq instrumentation in our Ruby gem, and we switched to using our own Sidekiq middleware in early 2018. (Surprise! Skylight has had hidden support for Sidekiq instrumentation since version 2.0.)
We added support for Active Job and Delayed::Job a few months after that and set about testing the characteristics of the various Active Job processors to see how well they would play with Skylight. The good news is that most of them worked with minimal fuss, with the notable exception of Resque, which uses a fork-per-job model that causes Skylight to exit often before it has a chance to report its trace data (this is something we would still like to address).
We also started tracking the enqueuing of jobs on the web side, so you can now measure the actual benefit of enqueuing a job versus performing that work inline during a web request (enabled by default).
In addition to Ruby, the Skylight agent is also written in Rust—most importantly skylightd, the daemon that batches raw data from your server and sends it to our data collection infrastructure. On the Rust side of the agent, the biggest issue we had to address was another limitation that was originally designed around the web request model: traces could contain up to 2048 child nodes, but allocating any more than that would result in an error. This limitation is also reflected on the collector, so we decided that our best option to maintain compatibility with existing traces was to implement a “pruning” algorithm that could more-or-less intelligently discard nodes at the deepest level of the trace until the final count was under the limit (while this works well in practice, it's still on our roadmap of something we can continue to improve in the future).
The User Experience
As always, we prioritize providing a user experience that makes it easy to understand and act on your app’s performance data. Whenever we add a new feature, we are very careful that it doesn’t add unnecessary complexity to this user experience.
For this reason, one of the primary motivators for offering first-class background jobs support was to allow data about background jobs to be shown separately from data about web requests. The sidekiq-skylight gem—which many Skylight users were already using—lumps jobs data into the same bucket as web requests data. As you might imagine, this breaks many of Skylight’s aggregation features. ☹️
For example, the Response Timeline shows aggregate data about all of the responses in the selected time period. By lumping background jobs in with web requests, we might show “2 seconds” as a typical response time when your median web request response time is only 100 miliseconds and the median duration of your jobs is over a minute. In this case, “2 seconds” isn’t really telling you anything about your app’s performance.
Fortunately, most of the work to separate jobs data from web requests data was completed in order to release Skylight Environments. Specifically, we inserted the concept of an “App Component” between the “App” model and the data in the collector, which allows us to split an app’s data into multiple “buckets”—for example, “MyApp production web”, “MyApp staging web”, “MyApp production worker”, “MyApp staging worker”.
Splitting the background jobs UI from the web requests UI also allowed us to provide terminology specific to jobs. To this end, Krystan wrote a new “translation” helper that allows us to make context-aware changes to strings, so we can use different terminology on pages displaying background jobs.
You’ll also see your production background jobs data in the Skylight Trends feature, including Trends in the UI.
The Rollout
While the actual instrumentation of jobs was relatively straightforward, as one of the largest new features Skylight has ever rolled out, we spent a great deal of time developing techniques that would allow us to gradually onboard our existing customers without affecting the existing user experience. In general we focused on keeping changes small and individually manageable. Highlights include:
- Moving storage of UI-related feature flags to the server, which allowed us to integrate it with our permissions system. During the alpha and beta phases, the new “process type” drop down selector would only be shown to specific users, so the new server-side flags would allow us greater control over who could see that menu (previously, we would have asked users to individually enable flags to see new features).
- A new “survey” feature that allows us to collect information and automatically group cohorts of users in our CRM, which was used to impanel an alpha testing group for the background jobs feature.
- A restructuring of our agent authorization endpoint to ensure that only users with permissions to use the pre-release background jobs features would be able to collect data.
- Improved logic around deciding what background jobs usage is “billable”.
What else is new in 4.0?
In addition to adding support for background jobs, we also added:
- Active Storage instrumentation.
- Trace pruning, as mentioned above, for web requests in addition to jobs.
- Better instrumentation for Active Model Serializers and Action Controller content types.
- Improved error handling and logging.
- Changes necessary to be compatible with Rails 6!
Also, we dropped support for Ruby 2.2, which is end-of-life. For users using modern Ruby, the upgrade to 4.0 should be painless.
See the Skylight agent CHANGELOG for a full list of changes.
Thanks!
Throughout this process, we've used Skylight for Background Jobs to learn about and improve our own app's performance characteristics, and we've turned it into a feature that we hope you'll find useful as well. We're by no means finished, however. There are many improvements and planned features in the pipeline, so stay tuned for future updates!
Credits (in order of appearance)
Collector Infrastructure Improvements: Godfrey and Zach
App Management Infrastructure Improvements: Zach and Krystan
User Interface Rejiggering: Krystan
Agent Updates: Peter and Zach
Documentation and Bloggering: Zach and Krystan
Dogfooding and Bug-finding: Zach and the Skylight Insiders
Haven't tried out Skylight yet? Sign up for your 30-day free trial! Or refer a friend and you both get $50 in credit.