Introducing Helix
Rust + Ruby, Without The Glue.
This post is a write-up of the talk I gave at RailsConf 2016. You can find the slides here.
There's a lot to love about Ruby – the sweet syntax, the focus on developer productivity and happiness, the mature ecosystem, and of course, the awesome community we built around the language.
One thing that Ruby is not known for though, is being a particularly fast language.
In the real world, a lot of real-world workloads are I/O bound, so this didn't end up mattering all that much. Since I/O operations (accessing your hard drive or database) are so much slower than the speed of the computations, the performance difference isn't really a bottleneck.
However, there are still plenty of CPU bound workload in the world, and you might occasionally encounter them in your application – number crunching, machine learning, image processing, video compression, etc. Sure, we have come a long way, but it is still prohibitively expensive to implement these kind of algorithms in pure-Ruby.
On the other end of the spectrum, there are low-level system languages like C. They have almost none of the features we love about Ruby, but since they are much Closer To The Metal™, you will be able to squeeze out every last drop of performance you need.
Native Extensions: Best Of Both Worlds
Fortunately, you actually can have your cake and eat it too. Ruby has a pretty awesome native extension API which allows you to implement the expensive computations in C but expose them via those sweet sweet Ruby APIs to your end-users.
For example, when you type gem install json in your terminal, you are actually getting two different implementations for the price of one. Included in the bundle is a module called JSON::Pure, which implements the entire JSON encoding/decoding API you know and love in pure-Ruby.
However, chances are that it will not be what you are actually using. If you system supports it, the gem will also compile and install a module called JSON::Ext, which re-implements the same API in C.
Needless to say, the C implementation is much faster than the pure-Ruby version, but otherwise there are no noticeable differences. This shows why the Ruby C API is so awesome – as far as your end-users can tell, it feels just like programming in Ruby and they will benefit from the performance boost without even knowing it.
Delivering Programmer Happiness
Just like Ruby, Rails is also pretty obsessed with programmer happiness. Here is a quote from David, the creator of Ruby on Rails:
Here’s a general value for Rails development: We will jump through hoops on the implementation to make the user-facing API nicer.
David Heinemeier Hansson
Take Active Support's core extension method String#blank? for example. Here is the code:
class String
# A string is blank if it's empty or contains whitespaces only:
#
# ''.blank? # => true
# ' '.blank? # => true
# "\t\n\r".blank? # => true
# ' blah '.blank? # => false
#
# Unicode whitespace is supported:
#
# "\u00a0".blank? # => true
#
def blank?
/\A[[:space:]]*\z/ === self
end
end
Note: This method received some improvements lately, but for the purpose of our discussion this slimmed down version works just fine.
This method checks if a given string is, well, blank, which is pretty handy for validating web forms and other kinds of user input. Since Ruby allows us to re-open core classes, we can simply add the method to the String class directly. Sweeeeet.
Perhaps because it is so sweet and so handy, this method is used extensively in a lot Rails apps, both in framework code and in user code. In fact, it is popular enough to be one of the performance hotspots for a lot of Rails apps.
Here is an idea. Why don't we implement this method C to make it faster?
That's exactly what [Sam Saffron](https://twitter.com/Sam Saffron) did with his fast_blank gem. All you need to do is to drop fast_blank into your Gemfile and everything Just Works™.
According to Sam, this implementation is up to 20X faster and could result in a 5% improvement on macro benchmarks. Well worth the trouble to make the developer experience nicer!
So, now that we have a good way to gracefully speedup pieces of code (and fall back to pure-Ruby implementations on unsupported platforms), aren't we done here? Why don't we do this more?
But... I Am Not A System Programmer 😳
Well, there is a problem... the problem is me.
You see, I – Godfrey, the Rails core team member – don't consider myself a system programmer. Sure, I have programmed in C before, so I know just enough to be dangerous. Give me a ptr, and I know how to add enough stars to make the compiler happy. If ******ptr doesn't work, maybe try &&&&&&&&&&&&&&&&ptr?
Okay, I'm being a bit hyperbolic here. But my point is, systems programming is hard. I don't mean it is hard to learn (although it is hard to learn), I mean that it is hard to get right. One small mistake, and you code could crash at runtime – or worse, behave unexpectedly and open up wild security vulnerabilities.
Am I really gonna trust myself to the responsibility of writing code that goes into everyone's Rails applications in C? Is the performance gain really worth the risk? Will I be able to find other contributors to help maintain the code?

Once upon a time, we had to face the same tradeoff here at Skylight.
The first version of the Skylight agent was written in Ruby. Since we need to hook into Rails, a Ruby agent is the natural choice. That solution lasted us a while, but we soon ran into performance and memory issues.
Since the Skylight agent is an always-on profiler that lives inside our customers' production applications, one of our highest priorities is to keep the overhead as minimal as possible – say, comparable to using syslog for logging.
We were able to keep it more-or-less under control in the Ruby agent, but as we looked into adding features like allocation tracking, the performance penalty got prohibitively expensive.
The answer has always been obvious – just rewrite the agent as a native extension. However, the same questions remain:
Even though our engineers do understand the difference between the reference and dereference operators, do we really feel comfortable putting our C code in customers' production applications? Can we afford the risk? Will everyone on our team be able to work on the code and keep shipping new features?
Could there be an alternative to C (and C++) that gives us the Best Of Both Worlds™?
Hack Without Fear
Meet Rust, a "systems programming language that runs blazingly fast, prevents segfaults, and guarantees thread safety". That's plenty of buzzwords to swallow, so I'll try to break it down a little.
Just like C (and unlike Ruby), Rust is a compiled, statically-typed language. Before your code can be executed, you must first run it through the compiler, which checks for and prevents a large amount of programmer errors. Instead of allowing them to bubble up at runtime and potentially crashing your program, the compiler would just refuse to compile your code.
Unlike C, Rust has a sufficiently advanced type system (and a carefully designed set of features), which allows the compiler to guarantee runtime memory safety.
This means that if you have successfully compiled a Rust program, it will not segfault at runtime.
The memory safety guarantee might sound ludicrous if you are coming from a system programming background, but of course high-level languages like Ruby have always provided this kind of guarantee. You simply cannot perform an operation in Ruby that would cause the VM to access memory illegally and segfault.
What is neat about this is that the Rust team has figured out how to guarantee memory safety without a garbage collector. Rust has a pretty cool ownership system that both eliminates the need for manual memory management and eliminate whole classes of memory management hazards. As a nice bonus, the lifetime-tracking also makes it possible to handle concurrency without data races.
Zero-cost Abstractions
So the safety aspect is nice, but to me Rust's coolest meta-feature is zero-cost abstractions.
In languages like Ruby, there is often a tension between writing/using high-level abstractions and performance.
For example, it would be nice to split up a big method into a bunch of smaller methods, but method calls aren't free; using things like each and map is nice, but they are much slower than a hand-crafted loop; Symbol#to_proc is sweet, but it comes with a pretty heavy performance penalty.
A lot of times, these details doesn't matter, but in performance-sensitive areas, every little thing counts.
In Rust, you don't have to make these kind of trade-offs.
As a compiled-language, Rust (just like C and C++) is able to deeply analyze your code at compile-time and eliminate the runtime cost associated with almost all kinds of abstractions. This allows you to liberally modularize your code for maintainability without sacrificing performance.
In fact, the Rust compiler can produce faster code when you use high-level constructs. For example, when you use an iterator, Rust can eliminate bounds checks that would be necessary to guarantee safety in a hand-rolled loop. By giving the compiler more information to work with, it will be able to do a better job at optimizing your code.
I cannot get into much more detail here. If you would like a high-level overview of Rust, you can watch Yehuda's talk from last year. He also went into detail about Rust's ownership system in Rust Means Never Having to Close a Socket.
Back To fast_blank
Remember fast_blank? Let's take a look at its implementation:
static VALUE
rb_str_blank(VALUE str)
{
rb_encoding *enc;
char *s, *e;
enc = STR_ENC_GET(str);
s = RSTRING_PTR(str);
if (!s || RSTRING_LEN(str) == 0) return Qtrue;
e = RSTRING_END(str);
while (s < e) {
int n;
unsigned int cc = rb_enc_codepoint_len(s, e, &n, enc);
switch (cc) {
case 9:
case 0xa:
case 0xb:
case 0xc:
case 0xd:
case 0x20:
case 0x85:
case 0xa0:
case 0x1680:
case 0x2000:
case 0x2001:
case 0x2002:
case 0x2003:
case 0x2004:
case 0x2005:
case 0x2006:
case 0x2007:
case 0x2008:
case 0x2009:
case 0x200a:
case 0x2028:
case 0x2029:
case 0x202f:
case 0x205f:
case 0x3000:
/* found */
break;
default:
return Qfalse;
}
s += n;
}
return Qtrue;
}
This code basically just loops through each character of the string, comparing each character against a list of whitespace characters. If we see anything that is not one of those characters, the string is not blank. Otherwise, if we got to the end, we know the string is blank.
One of the tricky things about this implementation is handling Unicode correctly. For one thing, you need to carefully enumerate all of the known Unicode whitespace characters by hand (which could change!). Also, since UTF-8 characters can span multiple bytes, looping through them is not as simple as incrementing a pointer (that's what rb_enc_codepoint_len is for).
But all in all, 50 lines of code for a transparent 20X speedup, not bad at all.
Let's try to implement this function in Rust:
pub extern "C" fn fast_blank(buf: Buf) -> bool {
buf.as_slice().chars().all(|c| c.is_whitespace())
}
Yep. That's it! We first convert the Ruby string into a "slice" type that Rust understands, call chars() on it to get an iterator, and use the .all() method to check if all the (unicode) characters matches the predefined whitespace rules using a closure. Finally, Rust implicitly returns the value of the last statement in a function, so there is no need to write return here.
Once you get past the differences in the syntax, this actually looks surprisingly like the Ruby code we are used to writing. Since we are using things like closures and iterators, it must be much slower than the hand-crafted C version, right?
Well, let's see how they compares in a benchmark!
=========== Test String Length: 6 ===========
Rust 11.043M (± 3.5%) i/s - 54.744M
C 10.583M (± 8.5%) i/s - 52.464M
Ruby 964.469k (±27.6%) i/s - 4.390M
Note: numbers reported are iterations per second, higher is better.
Wow! Surprisingly, this one-liner performs pretty similarly to the C version. In fact, it might actually be faster! Of course, that is not a very scientific claim, but I hope you will be convinced that you can indeed write high-level, perfectly safe code in Rust (just like you can in Ruby) that performs in the same ballpark as the equivalent C code.
The Magician's Secret
Alright, I have a confession to make. I haven't been completely honest with you. While the sweet sweet Rust one-liner is much shorter than the C version, that's not all the code you need to write when writing a native extension. To make it work, you need to write plenty of glue code in both the C and the Rust version. Let's take a look:
#include <stdio.h>
#include <ruby.h>
#include <ruby/encoding.h>
#include <ruby/re.h>
#define STR_ENC_GET(str) rb_enc_from_index(ENCODING_GET(str))
static VALUE
rb_string_blank(VALUE str)
{
rb_encoding *enc;
char *s, *e;
enc = STR_ENC_GET(str);
s = RSTRING_PTR(str);
if (!s || RSTRING_LEN(str) == 0) return Qtrue;
e = RSTRING_END(str);
while (s < e) {
int n;
unsigned int cc = rb_enc_codepoint_len(s, e, &n, enc);
switch (cc) {
case 9:
case 0xa:
case 0xb:
case 0xc:
case 0xd:
case 0x20:
case 0x85:
case 0xa0:
case 0x1680:
case 0x2000:
case 0x2001:
case 0x2002:
case 0x2003:
case 0x2004:
case 0x2005:
case 0x2006:
case 0x2007:
case 0x2008:
case 0x2009:
case 0x200a:
case 0x2028:
case 0x2029:
case 0x202f:
case 0x205f:
case 0x3000:
break;
default:
return Qfalse;
}
s += n;
}
return Qtrue;
}
void Init_fast_blank()
{
rb_define_method(rb_cString, "blank?", rb_string_blank, 0);
}
// Rust Code
extern crate libc;
use std::{ptr, slice};
use std::marker::PhantomData;
#[repr(C)]
#[allow(raw_pointer_derive)]
#[derive(Copy, Clone)]
pub struct Buf<'a> {
ptr: *mut u8,
len: usize,
marker: PhantomData<&'a ()>,
}
impl<'a> Buf<'a> {
pub fn as_slice(self) -> &'a str {
unsafe {
let s = slice::from_raw_parts(self.ptr as *const u8, self.len);
std::str::from_utf8_unchecked(s)
}
}
}
#[no_mangle]
pub extern "C" fn fast_blank(buf: Buf) -> bool {
buf.as_slice().unwrap().chars().all(|c| c.is_whitespace())
}
// C Code
#include <ruby.h>
#include <ruby/encoding.h>
typedef struct {
void* data;
size_t len;
} fast_blank_buf_t;
static inline fast_blank_buf_t
STR2BUF(VALUE str)
{
return (fast_blank_buf_t) {
.data = RSTRING_PTR(str),
.len = RSTRING_LEN(str),
};
}
int fast_blank(fast_blank_buf_t);
static VALUE
rb_string_blank_p(VALUE str)
{
return fast_blank(STR2BUF(str)) ? Qtrue : Qfalse;
}
void Init_fast_blank()
{
rb_define_method(rb_cString, "blank?", rb_string_blank_p, 0);
}
The highlighted portions are the C and Rust snippets I have shown previously. The code around it is the glue code you need to write to make the extension work. So even though the body of the Rust function is much shorter, if you include the glue code, they add up to be almost the same amount of code.
This is not all bad news. For one thing, we turned to Rust because we wanted speed and safety. If we get those two things with the same amount of code, it's still a big win. Furthermore, the function body is the logic that is actually unique to the extension, which is a cost we have to pay for every new method we want to add; whereas the glue code is largely boilerplate that can be shared and reused.
If the glue code is sharable, wouldn't it be great if someone did the work to extract them into a library?
Meet Helix
Well, I'm glad you asked! Yehuda and I have been working on a project called Helix. Helix is a bridge between Rust and Ruby (it's also a real bridge) and part of Dave Herman's grand plan for the Rust Bridge project.
Let's look at how we would implement fast_blank with Helix:
#[macro_use]
extern crate helix;
declare_types! {
reopen class RubyString {
def is_blank(self) -> bool {
self.chars().all(|c| c.is_whitespace())
}
}
}
Yepppppppp. That's it! For realz this time. Promise.
Thanks to Rust's macro system, we were able to abstract away a lot of the verbosity and distill it down to the parts you actually care about, in a syntax that should be pretty familiar to Rubyists. (A big thank you to Dave for paving the way.)
Behind this deceptively small amount of code, Helix is handling a lot for us under the hood, such as safe, transparent type-transport between Ruby and Rust. This is particularly important for handling user-supplied method arguments.
In the Ruby C API, each Ruby object – be it a String, Array or an Active Record object – are all represented as VALUEs, which is just an alias for void *. This is problematic, because most C APIs expect particular kinds of objects and could potentially segfault if passed the wrong kind of object. Since almost all of these functions simply claim to take a VALUE, the C compiler will not be able to perform any useful compile time checks.
In Helix, we were able to encode and enforce the required runtime checks into the Rust type system, which allows the compiler to check for any errors at compile time. For example:
#[macro_use]
extern crate helix;
declare_types! {
class Console {
def log(self, message: String) {
println!("{:?}", message);
}
}
}
This defines a Ruby class called Console with an instance method log that takes a single Ruby String as input. This macro transparently checks that the user has supplied the right argument (or raises a TypeError otherwise) and transparently converts that into the Rust type according to the signature (a Rust String in this case).
All in all, Helix makes it much more ergonomic to write Ruby native extensions while providing much stronger safety guarantees. The project is still in early development phase, but we think it has shown a lot of potential.
Turbo Rails?
With Rails reaching version 5.0, there are plenty of APIs that are heavily used and extremely feature-stable. My goal with Helix is to eventually make it possible to reimplement a lot of these APIs as an native extension gem.
In my opinion, fast_blank has proven that the strategy works well – since Rails already ships with a perfectly fine pure-Ruby implementation, there is always a good fallback option on unsupported platforms. Furthermore, these features usually have very good test coverage in Rails – so all we have to do to ensure compatibility is to run the native implementations against the Rails test suite.
My next milestone is to reimplement something like Active Support's Duration class or the Inflector module in Helix. Eventually, I hope to be able to implement bigger pieces like Rails' JSON encoder or the Rails router natively. There is still a long way to go, but I think it is a worthwhile project to pursue.
What About My App?
Speeding up Rails for everyone is great, but a lot of times the biggest gains come from tuning application code.
While working on Helix, our friends at Zesty showed us an interesting problem they encountered in their app. Zesty is catering company based in San Francisco.
It turns out serving thousands of meals every day is a trickier problem than you might expect. One of the challenges is that a lot of their customers have special meal preferences – including allergies and other dietary restrictions for medical or religious reasons.
According to our friends there, their meal-matching algorithm – currently written in pure Ruby – is one of their biggest bottlenecks, sometimes taking up to 30 minutes to complete. In particular, their profiles have shown that a lot of time was spent running the following query: does a given meal fully satisfy a set of constraints?
>> meal.features
=> [3, 6, 18, 34, 50]
>> meal.features.fully_contains?([3, 18, 34])
=> true
>> meal.features.fully_contains?([6, 18, 42])
=> false
As you can see, because both the features and the constraints are modeled as a sorted array of unique integers, this boils down to checking whether the first array fully contains all the items in the second array, in other words, a set containment problem.
Since this is a pretty common problem, there is a Known Trick™ for solving it. If you look on Stack Overflow or a Ruby programming book, you will probably find the following snippet:
class Array
def fully_contain?(other)
self & other == other
end
end
A sweet, sweet one-liner, just like you would expect. (Did I mention I love writing Ruby?) This piece of code works by first doing an intersection of the two arrays (i.e. producing a new array with only the items that are shared by the two arrays). Since the arrays are both pre-sorted, you can then compare the intersection with the second array – if they have exactly the same items in them, we know we have found a match.
While this one-liner is very elegant (and works well for many use cases), it is not as efficient as it could be as it doesn't take full advantage of the known parameters in our particular problem. For instance, we know the two arrays are pre-sorted and contains no duplicates – but Ruby's array intersection implementation does not. Furthermore, the & operator has to allocate a new intermediate array, causing unnecessary GC pressure.
Given what we know, we can do much better than this:
class Array
def fully_contain?(needle)
return true if needle.empty?
return false if self.empty?
needle_length = needle.length
return false if needle_length > self.length
needle_position = 0
needle_item = needle[needle_position]
self.each do |item|
if item == needle_item
needle_position += 1
if needle_position >= needle_length
return true
else
needle_item = needle[needle_position]
end
end
end
false
end
end
This version of the algorithm avoids the unnecessary book-keeping and allocations, and finds the answer in a single-pass. It works by keeping two pointers into the two arrays and increment them as we find possible matches. I won't get into too many details here, but you can take my word for it that it works. (We ran the tests!)
So, how does this compare against the naïve implementation? We ran some benchmarks on a series of different work loads, from what we can tell, this is around 2 times faster on the typical cases but could be up to 7 times faster. (Keep in mind our standalone benchmarks probably do not replicate the full effect of the GC issues in the real app.) Not bad at all!
Now that we have solved the Google interview question, why don't we try to implement this in Helix?
#[macro_use]
extern crate helix;
declare_types! {
reopen class Array {
def fully_contain(self, needle: &[usize]) -> bool {
if needle.is_empty() { return true }
if self.is_empty() { return false }
if needle.len > self.len { return false }
let mut needle = needle.iter();
let mut needle_item = needle.next().unwrap();
for item in self {
if item == needle_item {
match needle.next() {
None => return true,
Some(next_item) => needle_item = next_item
}
}
}
false
}
}
}
This is actually surprisingly readable! If you are already familiar with the syntax, it's arguably more readable – instead of manually managing the pointers like we did in Ruby, we were able to use high-level features like iterators. Ironically, using iterators here actually makes things faster, as the compiler is able to understand your intent and optimize out some unnecessary bound-checks.
So how does it compare with the Ruby versions? According to our benchmarks, the Rust implementation is consistently 10-20 times faster for the common cases but goes all the way up to 173 times faster than the naïve Ruby implementation! Of course, this is not a very scientific claim, but I hope to at least convince you that the potential is there.
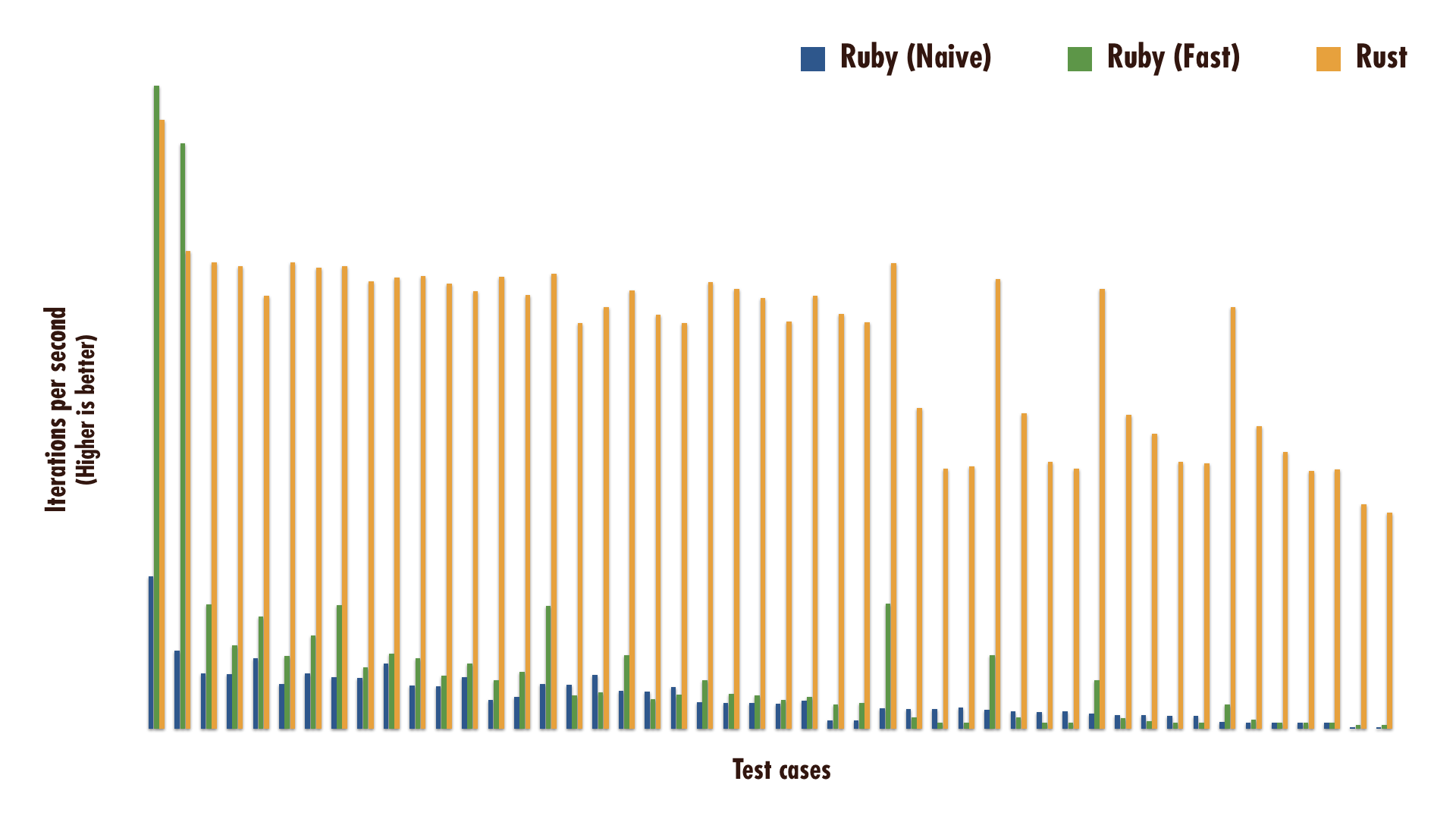
Ruby Without Fear
Scripting languages are intrinsically slower than systems languages. Historically, they were designed to be used as a coordination layer and delegate to the heavier tools written in system languages like C. For example, you might write a shell script in Bash that delegates to tools unix utilities like sort, grep and wc for the heavy-lifting.
As I mentioned before, since many real-world workloads turn out to be I/O bound, and because scripting languages are so much more pleasant to use and easy to iterate on, we end up moving more and more of our code into the scripting layer instead of writing everything in system languages. Since web applications are especially I/O-heavy, that worked out wonderfully for Rails.
But we're now entering a new era where programming language implementors have taken more and more of the ergonomics of scripting languages to performance-critical languages, or even systems languages like Rust.
Our goal with the Helix project is to let you keep writing the Ruby you love, without fearing that you'll eventually hit a wall. With Helix, you can always start with Ruby, knowing that you will always have the option to move only the CPU-intensive parts to Rust instead of rewriting your entire app in a faster language (or spawning a fleet of micro-services written in Go).
In my opinion, Rust is particularly suited for this task among Ruby teams. Thanks to the strong safety guarantees built into the Rust compiler and a strong focus on abstractions, more of your team members will be able to tinker with the Rust code without worrying about introducing subtle bugs – the worst that could happen is that the program doesn't compile.
On our team, every engineer ended up picking up enough Rust to be able to fix bugs or make tweaks to our Rust agent, and we think it will continue to be true as we grow.
That's our story with Helix. There's still plenty of work to do, but the future is bright. Let's #MakeRubyGreatAgain!
Update: we announced some updates to Helix recently, check out our new blog post!